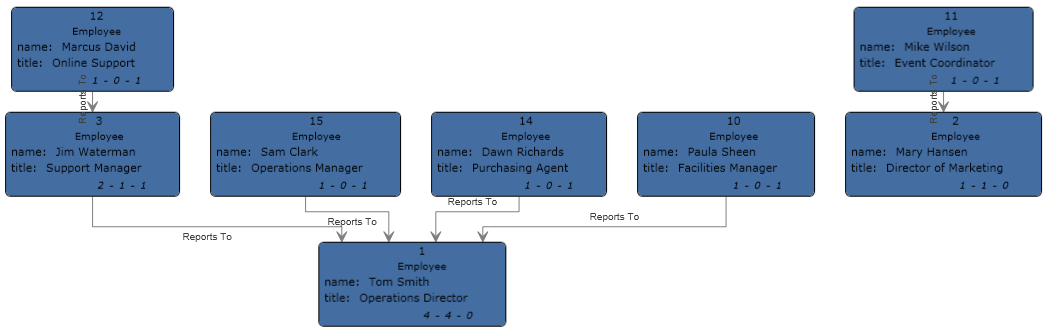
Flat-Beispiel
Konfigurieren von „Read from File“
Der „Write to Hub“-Datenfluss, der einen Flatfile für die Eingabe verwendet, sieht wie folgt aus:
- Mitarbeiter-ID
- Bezeichnung
- Titel
- Manager-ID

Sie werden feststellen, dass zwei Mitarbeiter keine Manager-IDs haben. Bei beiden Mitarbeitern (Tom Smith und Mary Hansen) handelt es sich um Geschäftsführer. Diese haben daher keinen Manager in dieser Übung. Alle anderen Mitarbeiter haben eine Nummer im ManagerID-Feld, die sich auf den Mitarbeiter bezieht, der ihr Manager ist. Zum Beispiel hat der Datensatz von Paula Sheen eine „1“ im Feld „ManagerID“, was darauf hinweist, dass Tom Smith ihr Manager ist.
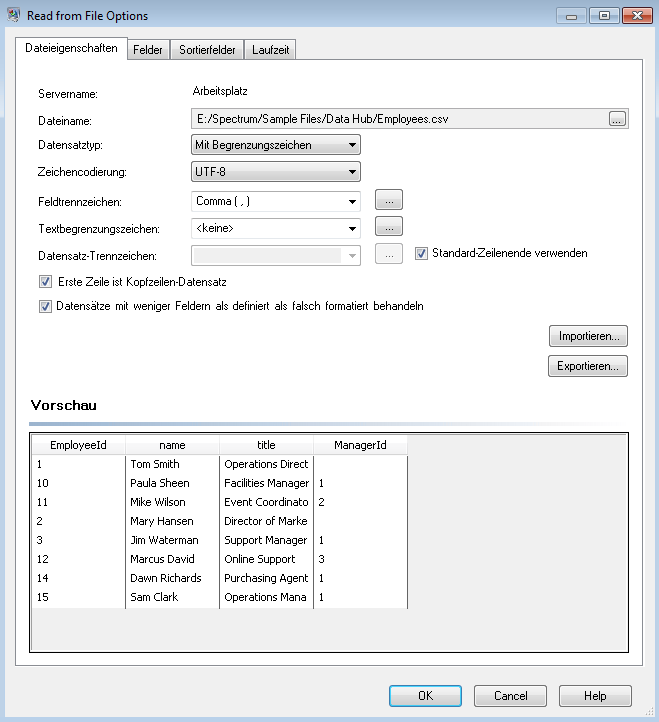
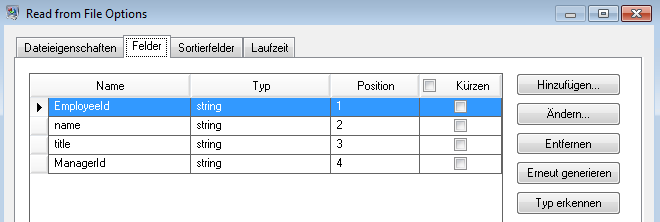
Der „Read from File“-Schritt wird folgendermaßen angezeigt, wenn sie für die Arbeit mit dieser Eingabedatei konfiguriert ist:
In einem nächsten Schritt konfigurieren wir den „Write to Hub“-Schritt. Nach der Benennung des Modells „Employees“ konfigurieren wir den Schritt, um die Entitäten und Beziehungen einzuschließen, aus denen das Modell bestehen wird.
Da wir ein Modell erstellen, das einem Organigramm ähnlich ist, sind unsere Entitäten Mitarbeiter, denen numerische IDs zugeordnet sind. Klicken Sie zunächst auf dem Dialogfeld Entität hinzufügen auf die Schaltfläche „Durchsuchen“, um auf das Dialogfeld Feldschema zuzugreifen, und wählen Sie anschließend „EmployeeId“ aus der Liste der verfügbaren Felder aus. Dies ist die erste Gruppe von Entitäten in unserem Modell.
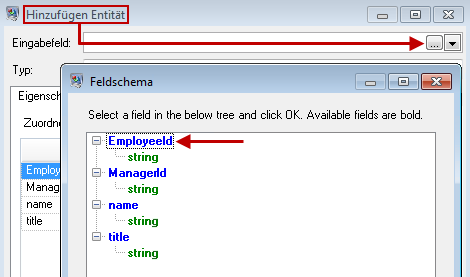
In einem nächsten Schritt stellen wir das Feld Typ auf „Employee“ ein und aktivieren die Kästchen für „Name“ und „Titel“, da die Informationen aus diesen Feldern als Eigenschaften für die Entitäten mit der Bezeichnung „EmployeeID“ im Modell gelten sollen.
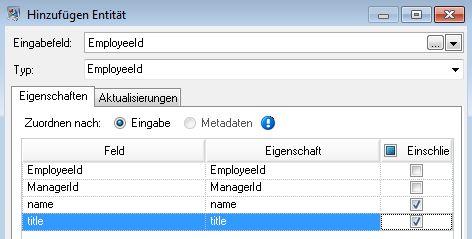
Nach dem Festlegen von Eigenschaften für die Entität „Employee“ konfigurieren wir die Verarbeitungsoptionen. Auf der Registerkarte „Aktualisierungen“ können Sie festlegen, ob Eigenschaften im Modell aktualisiert werden können, sobald sie eingestellt sind, und ob vorhandene Daten überschrieben werden sollen. In unserem Beispiel würde Mary Hansen zweimal auftreten, da sie auf Datensatz 4 als Mitarbeiterin bezeichnet wird, während sie auf Datensatz 3 als Manager bezeichnet wird. Wenn Mary zum zweiten Mal im „Write to Hub“-Schritt verarbeitet wird, können Daten, die infolge der ersten Verarbeitung von Mary aufgefüllt wurden, potenziell überschrieben oder entfernt werden. Wenn Eigenschaften nie mit leeren Daten überschreiben (Standardeinstellung) ausgewählt ist, erstellen alle auftretenden Aktualisierungen neue Eigenschaften und überschreiben vorhandene Eigenschaften. Sie werden jedoch keine Eigenschaften ausblenden, die bei der ersten Verarbeitung festgelegt wurden, in der zweiten Verarbeitung jedoch fehlen. Dadurch wird auch sichergestellt, dass die Reihenfolge, in der diese Datensätze gelesen werden, keine Auswirkungen auf das Modell hat.
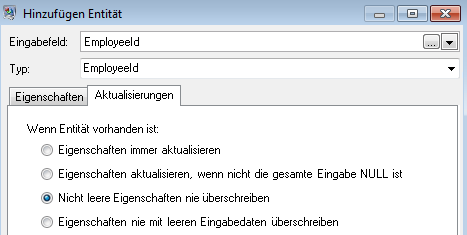
Wenn wir Eigenschaften immer aktualisieren ausgewählt haben, würden Daten immer überschrieben und nur die letzte Gruppe von Eigenschaftsdaten würde im Modell dargestellt werden. Wenn wir Eigenschaften aktualisieren, wenn nicht die gesamte Eingabe NULL ist ausgewählt haben, würden die Daten immer überschrieben werden, wenn nicht jedes Feld im neuen Datensatz leer wäre. Wenn wir schließlich Nicht leere Eigenschaften nie überschreiben ausgewählt haben, würde der erste Datensatz für ein beliebiges Feld beibehalten werden, es sei denn, das Feld ist leer. In diesem Fall würde der erste Satz von nicht leeren Daten beibehalten werden.
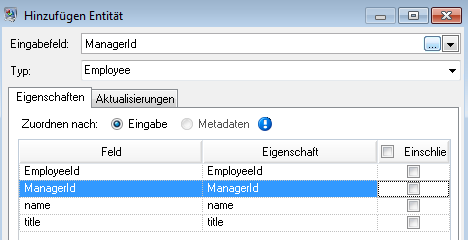
Wir wiederholen diese Schritte, um „ManagerId“ als zweite Gruppe von Entitäten in unserem Modell hinzuzufügen. Obwohl „ManagerID“ und „EmployeeID“ in der Eingabedatei unterschiedliche Felder sind, werden die beiden Entitätstypen auf „Employee“ eingestellt. Wenn wir die ManagerID auf einen anderen Typ einstellen, enthält das Modell zwei Entitäten für Manager der mittleren Führungsebene. Jim Waterman würde beispielsweise eine Entität als Mitarbeiter und eine Entität als Manager haben. Wenn beide Entitäten auf den Typ „Employee“ eingestellt sind, haben Manager der mittleren Führungsebene wie Jim nur eine Entität im Modell. Diese Entität wird andere eingehende (von den Mitarbeitern) und ausgehende (zu ihrem jeweiligen Manager) Entitäten aufweisen. Hinweis: Wir fügen den Entitäten mit der Bezeichnung „ManagerID“ keine Eigenschaften hinzu, da die Werte in diesen Feldern (Name, Titel) für die Mitarbeiter und nicht für die Manager gelten. Außerdem lassen wir die Standardauswahl von Eigenschaften nie mit leeren Daten überschreiben auf der Registerkarte „Aktualisierungen“ unverändert.
Die ausgefüllte Registerkarte „Entitäten“ wird für dieses Beispiel wie folgt angezeigt:
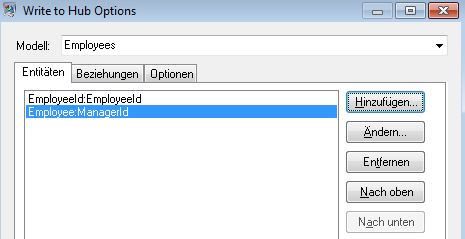
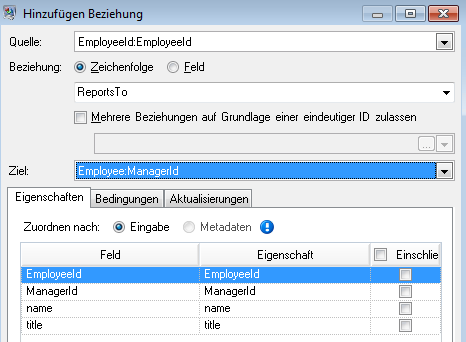
Nun konfigurieren wir die Registerkarte „Beziehungen“. Zunächst wählen wir im Dialogfeld Beziehung hinzufügen die Quelle der Beziehung aus der Liste der Entitäten aus, die auf der Registerkarte „Entitäten“ erstellt wurden. Die Beziehung zwischen unseren Entitäten spiegelt die Berichtsstruktur (Mitarbeiter zu Manager) wider. Daher wählen wir die Entität „Employee: EmployeeID“ als Quelle aus. In einem nächsten Schritt wählen wir „Zeichenfolge“ als Namen der Beziehung aus und geben den Text „Ist Untergebener von“ ein. Danach wählen wir das Ziel der Beziehung aus der Liste der auf der Registerkarte „Entitäten“ erstellten Entitäten aus. Für unser Beispiel wählen wir „Employee:ManagerID“. Wenn wir eine „Ist Vorgesetzter von“-Beziehung statt einer „Ist Untergebener von“-Beziehung verwenden, würden wir die Auswahl in den Quell- und Zielfeldern umkehren.
Die ausgefüllte Registerkarte „Beziehungen“ wird für dieses Beispiel wie folgt angezeigt:
Die Konfiguration dieses Datenflusses ist abgeschlossen und ergibt das folgende Modell (wie im Relationship Analysis Client dargestellt). In diesem Beispiel wird das Layout Hierarchisch mit Standardeinstellungen für Entitäten verwendet.
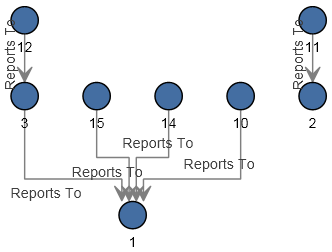
Diese Daten können auch mithilfe des Stils Bereich (siehe unten) angezeigt werden. Der Vorteil des Bereichsstils ist, dass Sie die mit jeder Entität verbundenen Eigenschaften anzeigen können.