Mise en correspondance d'enregistrements d'une source avec ceux d'une autre source
Cette procédure explique comment utiliser un stage Interflow Match pour identifier les enregistrements d'une source correspondant à ceux d'une autre source. La première source contient des enregistrements suspects et la deuxième source contient les enregistrements candidats. Le flux de données ne met en correspondance que les enregistrements d'une source avec ceux d'une autre source. Il n'essaie pas de mettre en corrsepondance des enregistrements issus de la même source. Le flux de données regroupe les enregistrements dans des collections d'enregistrements correspondants et écrit ces collections dans un fichier de sortie.
-
Faites glisser un stage Match Key Generator sur le canevas et connectez-le à l'un des stages source.
Par exemple, si vous utilisez un stage source Read from File, votre flux de données se présenterait désormais comme suit :
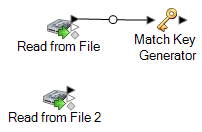
Match Key Generator crée une clé non unique pour chaque enregistrement, qui peut ensuite être utilisée par les stages de rapprochement pour identifier les groupes d'enregistrements doublons potentiels. Les match keys facilitent la procédure de correspondance en vous permettant de regrouper les enregistrements par match key, puis de ne comparer les enregistrements que dans ces groupes.
Remarque : Vous ajouterez un second stage Match Key Generator ultérieurement. Pour l'instant, vous n'en avez besoin que d'un sur le canevas. -
Connectez la copie du Match Key Generator à l'autre stage source.
Par exemple, si vous utilisez des stages d'entrée Read from File, votre flux de données se présenterait désormais comme suit :
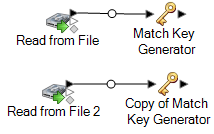
Le flux de données contient désormais deux stages Match Key Generator produisant des match keys pour toutes les sources utilisant exactement les mêmes règles. Il est essentiel que les stages Match Key Generator soient configurés de manière identique pour que ce flux de données fonctionne correctement.
-
Faites glisser un stage Interflow Match sur le canevas et connectez chacun des stages Match Key Generator à celui-ci.
Par exemple, si vous utilisez des stages d'entrée Read from File, votre flux de données se présenterait désormais comme suit :
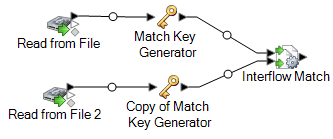
-
Faites glisser un stage de collecteur de données sur le canevas et connectez-le au stage Interflow Match.
Par exemple, si vous utilisiez un stage de collecteur de données Write To File, votre flux de données se présenterait comme suit :
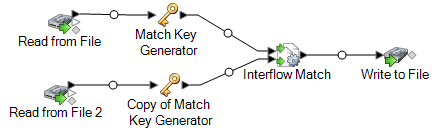
Vous disposez désormais d'un flux de données qui met en correspondance les enregistrements de deux sources de données.
Exemple de mise en correspondance d'enregistrements de plusieurs sources
En tant qu'entreprise de publipostage direct, vous souhaitez identifier les personnes figurant sur une liste d'expédition interdite, afin de ne pas leur envoyer de courrier direct. Vous disposez d'une liste de destinataires dans un fichier et d'une liste de personnes ne souhaitant pas recevoir de courrier marketing direct dans un autre fichier (fichier de suppression).
Le flux de données suivant offre une solution à ce scénario commercial :
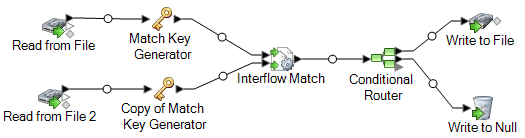
Le stage Read from File lit les données de votre liste de publipostage et le stage Read from File 2 lit les données de la liste de suppression. Les deux stages Match Key Generator sont configurés de manière identique, afin de produire une match key qui peut être utilisée par Interflow Match pour former des groupes de correspondances potentielles. Interflow Match identifie les enregistrements de la liste de publipostage figurant également dans la liste de suppression et marque ces enregistrements comme des doublons. Conditional Router envoie des enregistrements uniques, c'est-à-dire les enregistrements non trouvés dans la liste de suppression, au stage Write to File pour que celui-ci les écrive dans un fichier. Le stage Conditional Router envoie tous les autres enregistrements à Write to Null, où ils sont rejetés.