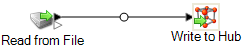
Ejemplo de archivo plano
Configuración de Read from File
El flujo de datos de Write to Hub que utiliza un archivo plano para la entrada tiene esta apariencia:
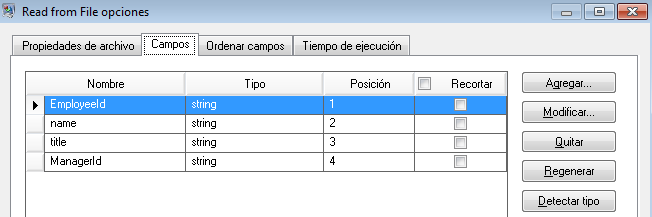
- Employee ID (ID de empleado)
- Nombre
- Título
- Manager ID (ID de gerente)

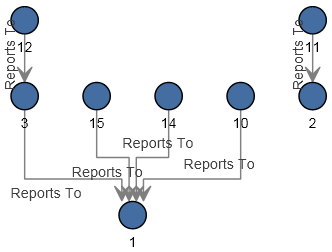
Como puede observarse, hay dos empleados sin ID de gerente. Estos empleados (Tom Smith y Mary Hansen) son directores, y por lo tanto no tienen gerentes respectivos en este ejercicio. Todos los demás empleados tienen un número en el campo ManagerID que hace referencia al empleado que se desempeña como el gerente respectivo. Por ejemplo, el registro de Paula Sheen muestra un "1" en el campo ManagerID para indicar que Tom Smith es su gerente.
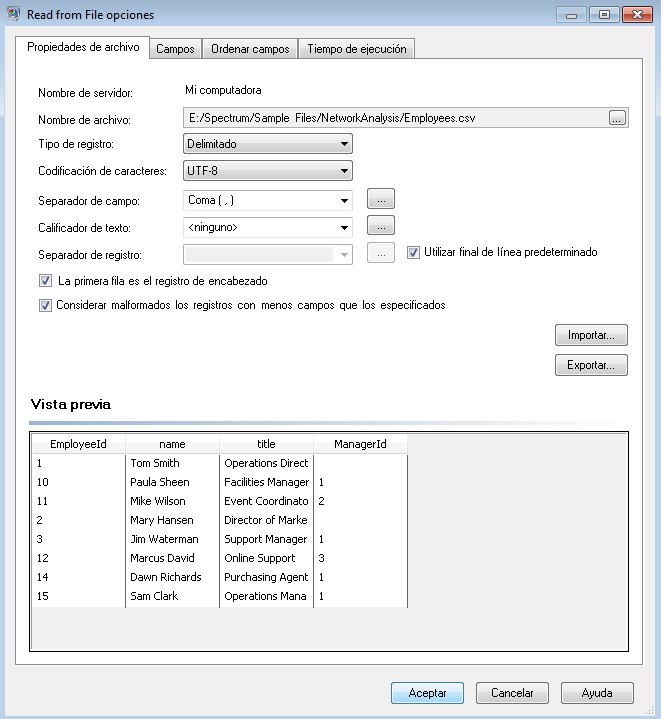
La etapa Read from File aparece de la siguiente manera cuando se configura para trabajar con este archivo de entrada:
A continuación se configura la etapa Write to Hub. Después de asignar al modelo el nombre "Empleados" ("Employees" en el ejemplo), la etapa se configura para incluir las entidades y relaciones que conforman el modelo.
Como estamos creando un modelo que es similar a un cuadro organizativo, nuestras entidades son empleados a los que se les asignan IDs numéricas. En primer lugar, en el cuadro de diálogo Agregar entidad hay que hacer clic en el botón Examinar para acceder al cuadro de diálogo Esquema de campo y luego seleccionar "EmployeeId" en la lista de campos disponibles. Este es el primer grupo de entidades de nuestro modelo.
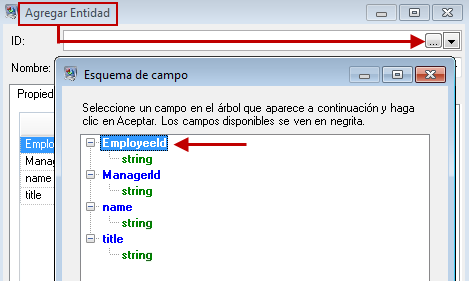
A continuación, establecemos el campo Tipo al valor "Employee" (Empleado) y marcamos las casillas de "nombre" y "título" porque deseamos que los datos de esos campos se incluyan como propiedades para las entidades EmployeeID en el modelo.
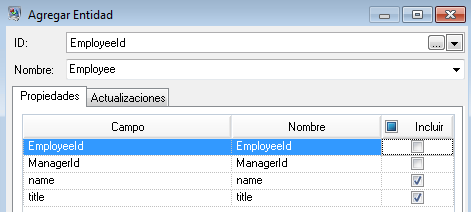
Después de configurar las propiedades para la entidad Empleado, debemos configurar las opciones de procesamiento. La ficha Actualizaciones permite especificar si las propiedades pueden actualizarse en el modelo después de implementarse y si deben sobrescribirse por encima de los datos ya existentes. Por ejemplo, en nuestro ejemplo Mary Hansen se encontrará dos veces porque en el registro 4 aparece como empleada y en el registro 3 aparece como gerente. Cuando la etapa Write to Hub procese a Mary por segunda vez, existe la posibilidad de que sobrescriba o elimine los datos que se habían completado durante el primer procesamiento de Mary. Al seleccionar No reemplazar nunca propiedades por datos vacíos (la opción predeterminada), todas las actualizaciones que se realicen crearán nuevas propiedades y sobrescribirán las propiedades anteriores, pero no eliminarán propiedades que se definieron para la primera instancia de encuentro y faltan en una segunda instancia. Esto también permite asegurarse de que el orden en el que se leen los registros no impacte en el modelo.
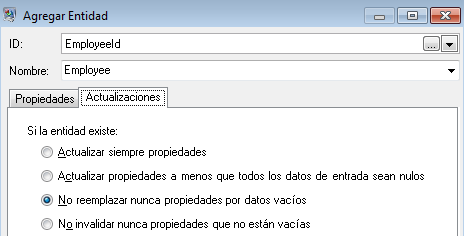
Si se seleccionara la opción Actualizar siempre propiedades, los datos siempre se sobrescribirían y solo el último conjunto de datos de propiedades se reflejaría en el modelo. Si se seleccionara la opción Actualizar propiedades a menos que todos los datos de entrada sean nulos, los datos siempre se sobrescribirían a menos que todos los campos del nuevo registro estuviesen en blanco. Por último, si se seleccionara la opción No invalidar nunca propiedades que no están vacías, el primer conjunto de datos de cualquier campo dado se conservaría a menos que el campo esté en blanco. En ese caso, se conservaría el primer conjunto de datos que no están en blanco.
Estos pasos se repiten para agregar "ManagerId" (ID de gerente) como el segundo grupo de entidades en el modelo. Aunque ManagerID y EmployeeID son diferentes campos en el archivo de entrada, los tipos de ambas entidades se establecen a "Employee". Si se establece ManagerID a un tipo diferente, el modelo contendría dos entidades para los administradores de nivel medio. Por ejemplo, Jim Waterman tendría una entidad como empleado y una entidad como gerente. Con ambas entidades definidas como entidades de tipo "Empleado", los gerentes de nivel intermedio como Jim Waterman tendrán solo una entidad en el modelo. Esa entidad tendrá otras incluidas (de los empleados) y otra derivada (al gerente respectivo). Cabe señalar que no se agregan propiedades a las entidades ManagerID porque los valores de esos campos (nombre, título, etc.) corresponden a los empleados, no a los gerentes. Asimismo, se acepta la opción predeterminada No reemplazar nunca propiedades por datos vacíos en la ficha Actualizaciones.

La ficha Entidades completa para este ejemplo aparece a continuación:
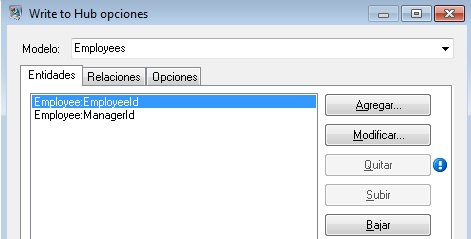
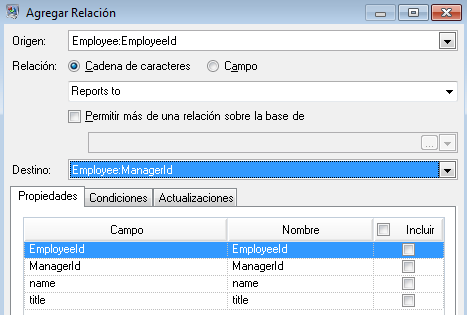
A continuación configuraremos la ficha Relaciones. Lo primero que debemos hacer en el cuadro de diálogo Agregar relación es seleccionar el origen de la relación de la lista de entidades creada en la ficha Entidades. La relación entre nuestras entidades refleja la estructura de subordinación (empleado a gerente). por lo tanto, seleccionaremos la entidad "Employee:EmployeeID" como origen. A continuación seleccionamos "Cadena de caracteres" como el nombre de la relación e introducimos el texto "Es subordinado de". Después de eso seleccionamos en la lista de entidades creadas en la ficha Entidades el destino de la relación; en nuestro ejemplo, seleccionamos "Employee:ManagerID". Si estuviésemos usando una relación "es jefe de" en lugar de una relación "es subordinado de" invertiríamos las selecciones en los campos de origen y destino.
La ficha Relaciones completa para este ejemplo aparece a continuación:
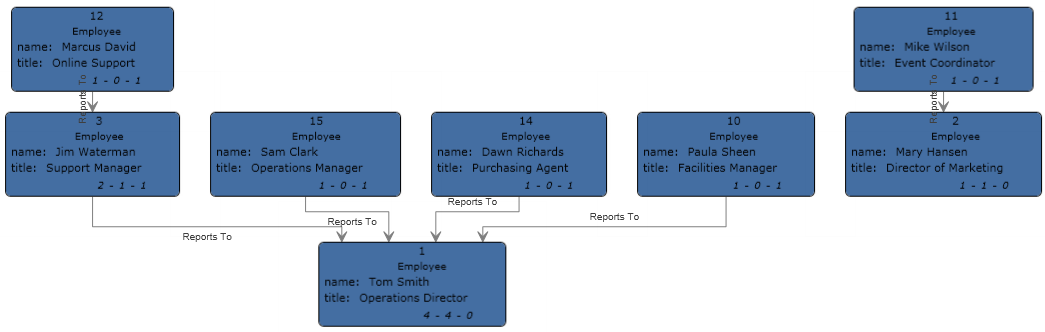
La configuración de este flujo de datos ya está completa y ha generado el siguiente modelo, según se describe en el Cliente de análisis de relaciones. En este ejemplo se utiliza el diseño Jerárquico con las opciones de configuración predeterminadas para las entidades.
Otra forma de ver los mismos datos es con el estilo Panel, como se muestra a continuación. El beneficio de usar este estilo consiste en poder ver las propiedades relacionadas con cada entidad.