SQL Command
SQL Command führt einen oder mehrere SQL-Befehle für jeden Datensatz im Datenfluss aus. Sie können SQL Command für Folgendes verwenden:
- Ausführen von komplexen INSERT/UPDATE-Anweisungen, wie Anweisungen, die Unteranfragen enthalten oder Verbindungen mit anderen Tabellen erstellen.
- Aktualisieren von Tabellen nach dem Einfügen/Aktualisieren von Daten, um die referenzielle Integrität zu wahren.
- Aktualisieren oder Löschen eines Datensatzes in einer Datenbank, bevor ein Ersatzdatensatz geladen wird.
- Aktualisieren von mehreren Tabellen in einer einzigen Transaktion.
Sie können vor und nach den SQL-Hauptbefehlen zusätzliche SQL-Befehle ausführen, und Sie können gespeicherte Prozeduren aufrufen.
Allgemeine Einstellungen
Auf der Registerkarte Allgemein können Sie dynamische SQL-Anweisungen festlegen, die Sie einmal für jeden Datensatz ausführen möchten. Die folgende Tabelle enthält die Optionen der Registerkarte Allgemein.
| Option | Beschreibung |
|---|---|
|
Verbindung |
Wählen Sie die gewünschte Datenbankverbindung aus. Die Auswahlmöglichkeiten variieren, je nachdem, welche Verbindungen im Verbindungs-Manager der Management Console definiert sind. Wenn Sie eine neue Datenbankverbindung herstellen oder eine vorhandene Datenbankverbindung ändern oder löschen müssen, klicken Sie auf Verwalten. Wenn Sie eine Datenbankverbindung hinzufügen oder ändern, füllen Sie diese Felder aus:
|
|
SQL-Anweisungen |
Geben Sie die SQL-Anweisungen ein, die Sie für jeden Datensatz im Datenfluss ausführen möchten. Mit Beginn der Eingabe erscheint ein Fenster, das automatisch die gültigen SQL-Befehle anzeigt. Trennen Sie mehrere SQL-Anweisungen mit einem Semikolon ( ; ). Verwenden Sie die folgende Syntax, um einen Wert in einem Datenflussfeld festzulegen:
Dabei steht Beispiel: In diesem Beispiel ersetzt Anmerkung: Anforderungen müssen den vollständig qualifizierten Namen verwenden. Beispiel: MeineDatenbank.dbo.customer.
|
|
Transaktionsverarbeitung |
Gibt an, ob Datensätze in Batches oder alle auf einmal verarbeitet werden können. Zur Auswahl stehen:
|
|
Fehlerverarbeitung |
Gibt an, was zu tun ist, wenn während der Ausführung der SQL-Befehle ein Fehler auftritt. Zur Auswahl stehen:
Anmerkung: Wenn in SQL ein Syntaxfehler auftritt, wird der Datenfluss ungeachtet der von Ihnen hier ausgewählten Einstellung immer beendet.
Zusätzlich können Sie optional Fehlerdatensätze in ein Laden von Daten schreiben, indem Sie den SQL Command-Fehlerport mit dem gewünschten Datenladungstyp verbinden. Der Fehlerport ist das weiße Dreieck auf der rechten Seite des Schrittsymbols im Datenfluss. Zum Schreiben von Fehlerdatensätzen in ein Flatfile müssen Sie z. B. den SQL Command-Fehlerport mit dem „Write to File“-Schritt verbinden, wie hier dargestellt: |
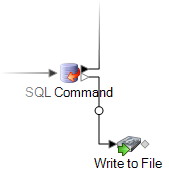
Pre-/Post-SQL
Auf der Registerkarte Pre/Post SQL legen Sie SQL-Anweisungen fest, die einmal pro Datenflussausführung ausgeführt werden sollen. Dies ist der Gegensatz zur einmaligen Ausführung pro Datensatz wie auf der Registerkarte Allgemein. Die folgende Tabelle enthält die Optionen der Registerkarte Pre-/Post-SQL.
| Option | Beschreibung |
|---|---|
|
Pre-SQL |
Geben Sie eine oder mehrere SQL-Anweisungen ein, die Sie ausführen möchten, bevor die in den Schritt eintretenden Datensätze verarbeitet werden. Die von Ihnen eingegebenen SQL-Anweisungen werden einmal pro Ausführung ausgeführt, nachdem der Datenfluss gestartet ist, aber bevor der „SQL Command“-Schritt die ersten Datensätze verarbeitet. Ein Beispiel für die Verwendung von Pre-SQL ist die Erstellung einer Tabelle für die zu verarbeitenden Datensätze. |
|
Automatischer Commit von Pre-SQL |
Aktivieren Sie dieses Kästchen, um die Pre-SQL-Anweisungen zu übergeben, bevor die SQL-Anweisungen auf der Registerkarte Allgemein ausgeführt werden. Wenn Sie dieses Kästchen nicht aktivieren, werden die Pre-SQL-Anweisungen in der gleichen Transaktion wie die SQL-Anweisungen auf der Registerkarte Allgemein übergeben. Anmerkung: Wenn Sie weder das Kästchen Automatischer Commit von Pre-SQL noch das Kästchen Automatischer Commit von Post-SQL aktivieren, werden alle SQL-Anweisungen für den Schritt in einer Transaktion übergeben.
|
| Post-SQL |
Geben Sie eine oder mehrere SQL-Anweisungen ein, die Sie ausführen möchten, nachdem alle Datensätze verarbeitet wurden. Die von Ihnen hier eingegebenen SQL-Anweisungen werden einmal pro Ausführung ausgeführt, nachdem der „SQL Command“-Schritt beendet ist, aber bevor der Datenfluss beendet wird. Eine Beispielanwendung von Pre-SQL wäre der Aufbau eines Index nach der Verarbeitung der Datensätze. |
|
Automatischer Commit von Post-SQL |
Aktivieren Sie dieses Kästchen, um die Post-SQL-Anweisungen in ihrer eigenen Transaktion zu übergeben, nachdem die SQL-Befehle der Registerkarte Allgemein übergeben wurden. Wenn Sie dieses Kästchen nicht aktivieren, werden die Post-SQL-Anweisungen in der gleichen Transaktion wie die SQL-Anweisungen auf der Registerkarte Allgemein übergeben. Anmerkung: Wenn Sie weder das Kästchen Automatischer Commit von Pre-SQL noch das Kästchen Automatischer Commit von Post-SQL aktivieren, werden alle SQL-Anweisungen für den Schritt in einer Transaktion übergeben.
|
Registerkarte „Laufzeit“
Die Registerkarte Laufzeit enthält Schrittoptionen und gibt Ihnen die Möglichkeit, Standardwertwerte für die Schrittoptionen zu definieren.
|
Feldname |
Beschreibung |
|---|---|
| Schrittoptionen | In diesem Abschnitt sind die Datenflussoptionen aufgeführt, die in der SQL-Abfrage dieses Schrittes verwendet werden. Zudem können Sie hier einen Standardwert für diese Optionen angeben. In der Spalte Name sind die Optionen aufgelistet. In der entsprechenden Spalte Wert können Sie die Standardwerte eingeben.
Anmerkung: Der hier angegebene Standardwert wird auch im Abschnitt Datenflussoptionen zu Schritten zuordnen des Dialogfeldes Datenflussoptionen angezeigt. Mithilfe der Dialogbox können Sie außerdem den Standardwert ändern. Wenn für Standardwerte einer Option unterschiedliche Werte über Schrittoptionen, Datenflussoptionen und Job Executor angegeben sind, gilt folgende Rangfolge: im Job Executor angegebener Wert > unter Datenflussoptionen definierter Wert > unter Schrittoptionen eingegebener Wert.
|