Die verteilte Verarbeitung nimmt Teile Ihres Datenflusses und verteilt die Verarbeitung dieser Teile auf ein Cluster von Spectrum™ Technology Platform-Servern. Ihr Datenfluss könnte beispielsweise Geocoding ausführen, und Sie könnten die Geocoding-Verarbeitung auf mehrere Spectrum™ Technology Platform-Knoten in einem Cluster verteilen, um die Leistung zu verbessern.
-
Entscheiden Sie, welche Schritte Ihres Datenflusses Sie verteilen möchten. Erstellen Sie anschließend einen Unterfluss, der die zu verteilenden Schritte enthält.
Verwenden Sie nicht die folgenden Schritte in einem Unterfluss, der für eine verteilte Verarbeitung verwendet wird:
- Sorter
- Unique ID Generator
- Record Joiner
- Interflow Match
Die folgenden Schrittsätze müssen zusammen in einem Unterfluss für eine verteilte Verarbeitung verwendet werden:
- Vergleichsschritte (Intraflow Match und Transactional Match) sowie Konsolidierungsschritte (Filter, Best of Breed und Duplicate Synchronization).
- Aggregator und Splitter
Schließen Sie keine anderen Unterflüsse innerhalb des Unterflusses ein (geschachtelte Unterflüsse).
Beachten Sie Folgendes, wenn Sie Vergleichsvorgänge in einem Unterfluss ausführen, der für eine verteilte Verarbeitung verwendet wird:
- Die Sortierung muss im Auftrag und nicht im Unterfluss erfolgen. Sie müssen die Sortierung im Schritt deaktivieren und die Sortierung auf Auftragsebene ausführen.
- „Match Analysis“ wird nicht in einem verteilten Unterfluss unterstützt.
- Sammlungsnummern werden innerhalb einer Mikrofluss-Batch-Gruppe erneut verwendet.
Die Verwendung eines „Write Exception“-Schrittes in einem Unterfluss könnte unerwartete Ergebnisse generieren. Stattdessen sollten Sie diesen Schritt Ihrem Datenfluss auf Auftragsebene hinzufügen.
-
Sobald Sie Ihren Unterfluss für den Teil des zu verteilenden Datenflusses erstellt haben, fügen Sie den Unterfluss dem übergeordneten Datenfluss hinzu und verbinden Sie ihn mit einem vor- und nachgestellten Schritt. Unterflüsse für eine verteilte Verarbeitung könnten nur einen Eingabeport haben.
-
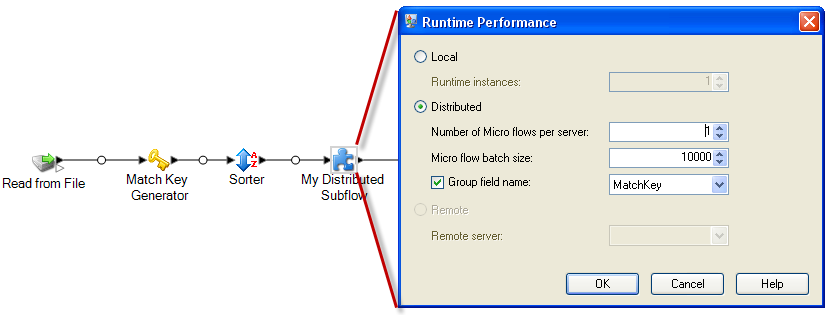
Klicken Sie mit der rechten Maustaste auf den Unterfluss, und wählen Sie Optionen aus.
-
Wählen Sie Verteilt aus.
-
Geben Sie die Anzahl der Mikroflüsse an, die an jeden Server geschickt werden sollen.
-
Geben Sie die Anzahl der Datensätze an, die in jedem Mikrofluss-Batch enthalten sein sollen.
- Optional:
(Optional) Aktivieren Sie Feldname gruppieren, und wählen Sie den Namen des Feldes aus, nach dem die Mikrofluss-Batches gruppiert werden sollen.
Wenn Sie ein Gruppenfeld bereitstellen, könnte Ihre Batchgröße größer als die im Feld Mikrofluss-Batchgröße angegebene Zahl sein, da eine Gruppe nicht auf mehrere Batches aufgeteilt wird. Wenn Sie beispielsweise eine Batchgröße von 100 angeben, die gleiche Gruppe jedoch 108 Datensätze enthält, umfasst dieses Batch 108 Datensätze. Wenn Sie eine Batchgröße von 100 angeben und eine neue Gruppe von 28 Datensätzen mit der gleichen ID bei Datensatz 80 beginnt, sind gleichermaßen 108 Datensätze in diesem Batch enthalten.
Das folgende Beispiel zeigt einen Datenfluss, für den ein Unterfluss mit dem Namen „My Distributed Subflow“ konfiguriert wurde, um im verteilten Modus ausgeführt zu werden: