ピボット テーブルの作成
ピボット テーブルとは、入力データに基づいてテーブルの行と列のカテゴリを作成することで、データを分析しやすいように集約するものです。詳細については、「 ピボット テーブル」を参照してください。
Group Statistics ステージのオプションで、次の操作を行います。出力列の名前は、命名規則 <Data>_<Operation>Of<InputFieldName> に従います。ここで、<Data> は最初のフィールドで指定した値、<Operation> は [操作] フィールドで選択した操作、<InputFieldName> は operation を実行する入力列です。
ピボット テーブルの例
以下は、サービス業務部門からの出荷情報を示す入力データです。
Region,State,County,ShipDate,Unit
East,MD,Calvert,1/31/2010,
East,MD,Calvert,6/31/2010,212
East,MD,Calvert,1/31/2010,633
East,MD,Calvert,6/31/2010,234
East,MD,Prince Georges,2/25/2010,112
East,MD,Montgomery,1/31/2010,120
East,MD,Baltimore,6/31/2010,210
East,VA,Fairfax,1/31/2010,710
West,CA,SanJose,1/31/2010,191
West,CA,Alameda,2/25/2010,411
West,CA,Los Angeles,2/25/2010,
West,CA,Los Angeles,2/25/2010,215
West,CA,Los Angeles,6/31/2010,615
West,CA,Los Angeles,6/31/2010,727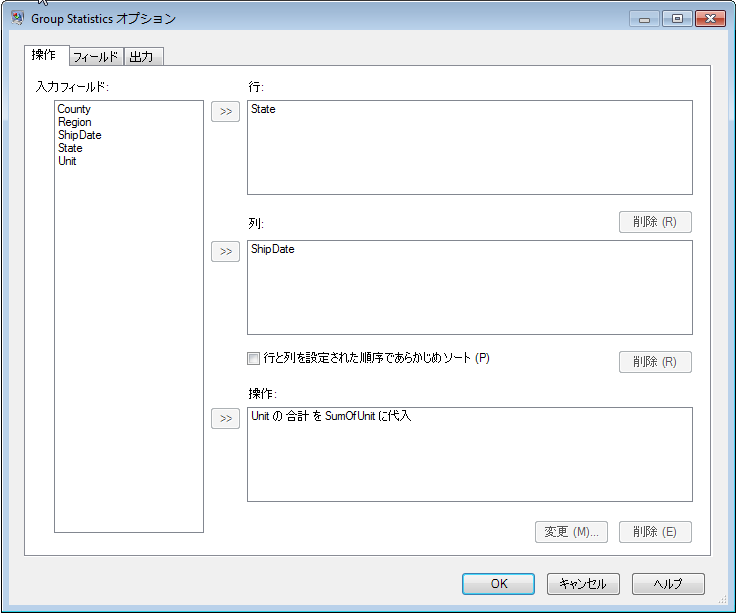
ステージ オプションの [フィールド] タブで、データフローの入力データの
ShipDate フィールドに出現する正確な日付をグリッドに追加し、各列値に対して表示する [操作] の値を選択します。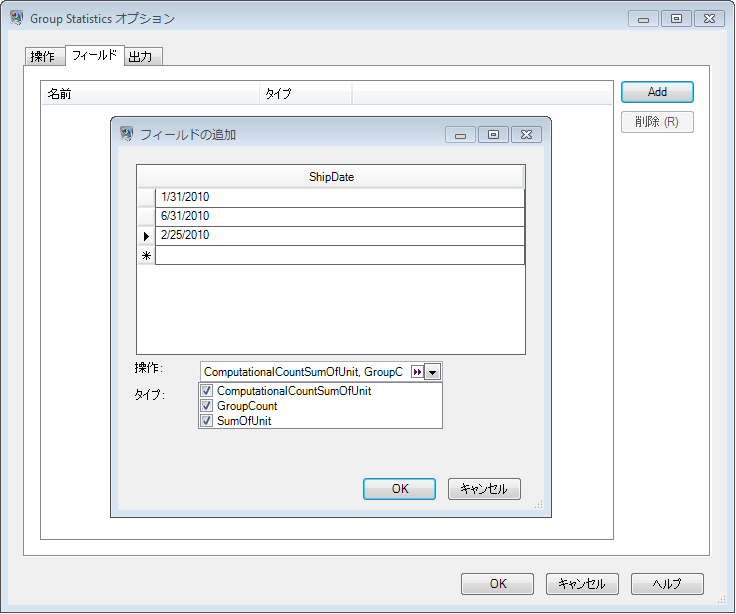
[フィールドの追加] ウィンドウの [OK] をクリックすると、作成された出力列が自動的に [フィールド] タブに一覧表示されます。これらの出力列は、正確な入力値と、[フィールドの追加] ウィンドウで選択した操作のデカルト積です。
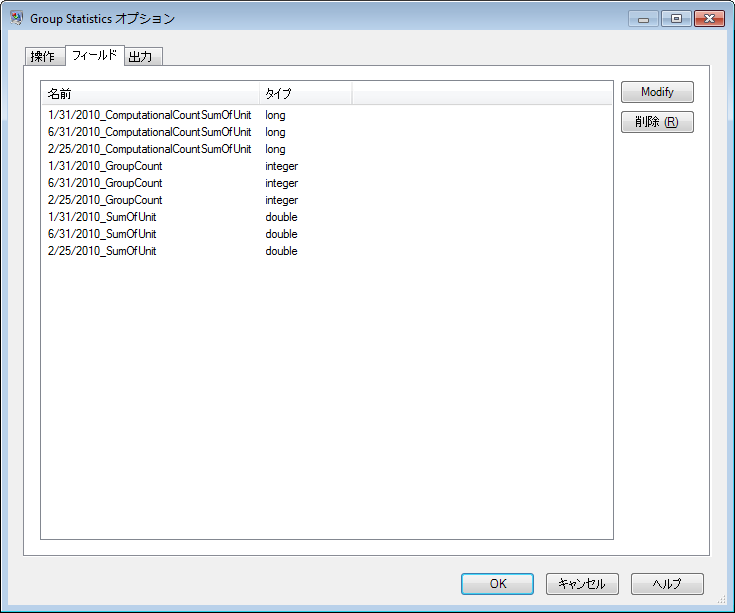
出力
State,1/31/2010_GroupCount,1/31/2010_ComputationalCountSumOfUnit,
1/31/2010_SumOfUnit,2/25/2010_GroupCount,2/25/2010_ComputationalCountSumOfUnit,
2/25/2010_SumOfUnit,6/31/2010_GroupCount,6/31/2010_ComputationalCountSumOfUnit,
6/31/2010_SumOfUnit
VA,1,1,710,,,,,,
CA,1,1,191,3,2,626,2,2,1342
MD,3,2,753,1,1,112,3,3,656