Cette procédure explique comment utiliser un stage Intraflow Match pour identifier les groupes d'enregistrements dans une source de données unique (telle qu'un fichier ou une table de base de données) reliés entre eux, en fonction des critères de correspondance que vous indiquez. Le flux de données regroupe les enregistrements dans des collections et écrit ces collections dans un fichier de sortie.
-
Dans Enterprise Designer, créez un flux de données.
-
Faites glisser un stage source sur le canevas.
-
Double-cliquez sur le stage source et configurez-le. Pour obtenir les instructions sur la configuration des stages source, reportez-vous au Guide du concepteur du flux de données.
-
Faites glisser un stage Match Key Generator sur le canevas et connectez-le au stage source.
Par exemple, si vous utilisez un stage source Read from File, votre flux de données se présenterait désormais comme suit :
Match Key Generator crée une clé non unique pour chaque enregistrement, qui peut ensuite être utilisée par les stages de rapprochement pour identifier les groupes d'enregistrements doublons potentiels. Les match keys facilitent la procédure de correspondance en vous permettant de regrouper les enregistrements par match key, puis de ne comparer les enregistrements que dans ces groupes.
-
Double-cliquez sur le Match Key Generator.
-
Cliquez sur Ajouter.
-
Définissez la règle à utiliser pour générer une match key pour chaque enregistrement.
Tableau 1. Options de Match Key Generator
|
Nom de l'option
|
Description/Valeurs valides
|
|
Algorithme
|
Définit l'algorithme à utiliser pour générer la clé de correspondance. L'un des éléments suivants :
- Consonne
- Renvoie les champs indiqués, les consonnes étant supprimées.
- Metaphone double
- Renvoie un code basé sur la représentation phonétique de leurs caractères. Le double Metaphone est une version améliorée de l'algorithme Metaphone et tente de prendre en compte les nombreuses irrégularités de plusieurs langues.
- Koeln
- Noms d'index par son, tels qu'ils sont prononcés en allemand. Permet aux noms ayant la même prononciation d'être encodés avec la même représentation afin qu'ils puissent être mis en correspondance, en dépit de différences mineures au niveau de l'orthographe. Le résultat est toujours une séquence de nombres ; les caractères spéciaux et les espaces blancs sont ignorés. Cette option a été développée en réponse aux limites du Soundex.
- MD5
- Algorithme qui produit une valeur hash de 128 bits. Cet algorithme est généralement utilisé pour vérifier l'intégrité des données.
- Metaphone
- Renvoie une clé codée Metaphone des champs sélectionnés. Metaphone est un algorithme qui code les mots à l'aide de leur sonorité lorsque prononcé en anglais.
- Metaphone (Espagnol)
- Renvoie une clé codée Metaphone des champs sélectionnés pour la langue espagnole. Cet algorithme Metaphone code les mots à l'aide de leur sonorité lorsque prononcé en espagnol.
- Metaphone3
- Procède à une amélioration en fonction des algorithmes Metaphone et Double Metaphone avec des paramètres de consonne et de voyelle interne exacts qui vous permet de produire des mots ou des noms mis en correspondance de manière plus ou moins proche pour rechercher des termes au niveau phonétique. Metaphone 3 augmente l'exactitude de l'encodage phonétique à 98 %. Cette option a été développée en réponse aux limites du Soundex.
- Nysiis
- L'algorithme de code phonétique qui met en correspondance une prononciation approximative avec une orthographe exacte et indexe des mots prononcés de manière similaire. Fait partie du système New York State Identification and Intelligence System. Imaginons, par exemple, que vous recherchez des informations sur une personne dans une base de données de personnes. Vous pensez que le nom de la personne sonne comme « John Smith », mais il est en fait orthographié « Jon Smyth ». Si vous procédez à une recherche de la correspondance exacte de « John Smith », aucun résultat n'est renvoyé. Cependant, si vous indexez la base de données à l'aide de l'algorithme NYSIIS et procédez à une recherche en utilisant de nouveau l'algorithme NYSIIS, la correspondance correcte est renvoyée car « John Smith » et « Jon Smyth » sont indexés comme « JAN SNATH » par l'algorithme.
- Phonix
- Pré-traite les chaînes de nom en appliquant plus de 100 règles de transformation à des caractères uniques ou à des séquences de plusieurs caractères. 19 de ces règles s'appliquent uniquement si les caractères figurent au début de la chaîne, tandis que 12 des règles s'appliquent uniquement si les caractères figurent au milieu de la chaîne et 28 des règles s'appliquent uniquement si les caractères figurent à la fin de la chaîne. La chaîne de nom transformée est cryptée en un code composé d'une lettre au début, suivie de trois chiffres (en enlevant les zéros et les nombres en double). Cette option a été développée pour répondre aux limites de Soundex ; elle est plus complexe et donc plus lente que Soundex.
- Soundex
- Renvoie un code Soundex des champs sélectionnés. Soundex produit un code de longueur fixe en s'appuyant sur la sonorité du mot lorsque prononcé en anglais.
- Substring
- Renvoie une partie spécifié du champ sélectionné.
|
|
Nom de champ
|
Indique le champ auquel vous souhaitez appliquer l'algorithme sélectionné pour générer la match key. Par exemple, si vous sélectionnez un champ appelé LastName et que vous choisissez l'algorithme Soundex, ce dernier est appliqué aux données dans le champ LastName pour produire une match key.
|
|
Position de début
|
Spécifie la position de départ dans le champ spécifié. Tous les algorithmes ne permettent pas de spécifier une position de départ.
|
|
Longueur
|
Spécifie la longueur de caractère à inclure à partir de la position de départ. Tous les algorithmes ne permettent pas de spécifier une longueur.
|
|
Supprimer les caractères parasites :
|
Supprime tout caractère non numérique et non alphanumérique, comme les traits d'union, les espaces blancs, et autres caractères spéciaux du champ d'entrée.
|
|
Trier les entrées :
|
Trie tous les caractères dans un champ d'entrée ou tous les termes dans un champ d'entrée par ordre alphabétique.
- Caractères
- Trie les valeurs de caractères d'un champ d'entrée avant de créer un identifiant unique.
- Termes
- Trie les valeurs de termes d'un champ d'entrée avant de créer un identifiant unique.
|
-
Lorsque vous avez terminé de définir la règle, cliquez sur OK.
-
Pour ajouter d'autres règles de correspondance, cliquez sur Ajouter et ajoutez-les, sinon cliquez sur OK lorsque vous avez terminé.
-
Faites glisser un stage Intraflow Match sur le canevas et connectez-le au stage Match Key Generator.
Par exemple, si vous utilisez un stage source Read from File, votre flux de données se présenterait désormais comme suit :

-
Double-cliquez sur Intraflow Match.
-
Dans le champ Charger une règle de rapprochement, sélectionnez une des règles de correspondance prédéfinies que vous pouvez utiliser tel quel ou modifier pour répondre à vos besoins. Si vous souhaitez créer une nouvelle règle de correspondance sans utiliser une des règles de correspondance prédéfinies comme point de départ, cliquez sur Nouveau. Vous ne pouvez disposer que d'une règle personnalisée dans un flux de données.
Remarque : La fonction Options de flux de données dans Enterprise Designer permet d'afficher la règle de correspondance pour la configuration au moment de l'exécution.
-
Dans le champ Grouper par, sélectionnez Match Key.
Cette opération aura pour effet de placer les enregistrements disposant de la même match key dans un groupe. La règle de correspondance s'applique aux enregistrements d'un groupe pour vérifier s'ils sont des doublons. La match key de chaque enregistrement est générée par le stage Generate Match Key que vous avez configuré précédemment dans cette procédure.
-
Pour plus d'informations sur la modification des autres options, voir Création d'une règle de correspondance.
-
Cliquez sur OK pour enregistrer votre configuration Intraflow Match et revenir au canevas du flux de données.
-
Faites glisser un stage de collecteur de données sur le canevas et connectez-le au stage Generate Match key.
Par exemple, si vous utilisiez un stage de collecteur de données Write To File, votre flux de données se présenterait comme suit :

-
Double-cliquez sur le stage de collecteur de données et configurez-le.
Pour obtenir des informations sur la configuration des stages de collecteur de données, reportez-vous au Guide du concepteur de flux de données.
Vous disposez désormais d'un flux de données qui met en correspondance les enregistrements d'une source unique.
Exemple de mise en correspondance d'enregistrements dans une source de données unique
En tant que data steward pour une nouvelle société de carte de crédit, vous souhaitez analyser la base de données de vos clients et déterminer quelles adresses ont plusieurs occurrences et sous quel noms, afin que vous puissiez minimiser le nombre d'offres de carte de crédit dupliquées, envoyées au même foyer.
Cet exemple expose la façon d'identifier les membres d'un même foyer en comparant les informations d'un champ d'entrée unique et en créant un fichier de sortie contenant un enregistrement par foyer.
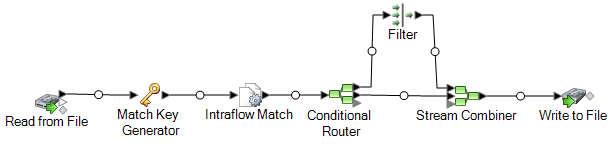
Le stage Read from File lit les données contenant des enregistrements uniques pour chaque foyer et des enregistrements éventuellement issus du même foyer. Le fichier d'entrée contient des noms et des adresses.
Match Key Generator crée une match key qui est une clé non unique partagée par des enregistrements semblables identifiant les enregistrements comme des doublons.
Le stage Intraflow Match compare les enregistrements présentant la même match key et marque chaque enregistrement comme un enregistrement unique ou comme l'un des différents enregistrements pour le même foyer.
Conditional Router envoie des enregistrements qui composent des collections d'enregistrements pour chaque foyer au stage Filter, qui filtre un seul enregistrement pour chaque foyer et l'envoie au stage Stream Combiner. Le stage Conditional Router envoie également des enregistrements uniques directement à Stream Combiner.
Enfin, le stage Write to File crée un fichier de sortie contenant un enregistrement pour chaque foyer.