Grammaires
Une grammaire de parsing valide contient :
- Une variable racine définit la séquence de jetons, ou modèle de domaine, comme variables de règle.
- Les variables de règle définissant l'ensemble valide de caractère et la séquence selon laquelle ces caractères peuvent survenir afin d'être considéré comme composant d'un modèle de domaine. Pour plus d'informations, reportez-vous à la section Commandes de la section de règles.
- Le champ d'entrée à analyser. Le champ d'entrée désigne le champ à analyser dans les enregistrements de données source.
- Les champs de sortie pour les données analysées produites. Les champs de sortie définissent l'emplacement où stocker chaque jeton produit analysé.
- Les caractères utilisés pour segmenter les données d'entrée que vous analysez. Les caractères de segmentation sont des caractères comme des espaces et des tirets définissant le début et la fin d'un jeton. Le caractère de segmentation par défaut est un espace. Les caractères de segmentation représentent la principale voie permettant de décomposer une séquence de caractères en un ensemble de jetons. Vous pouvez régler la commande Segmenter sur AUCUN pour empêcher la jetonization du champ. Lorsque la commande Segmenter est réglée sur Aucun, tout espace des règles de grammaire doit être compris dans la définition des règles.
- L’option de sensibilité à la casse pour les jetons se trouve dans les données d'entrée.
- Un caractère attaché permettant de délimiter les jetons correspondants.
- Mettre en correspondance des jetons dans des tableaux
- Mettre en correspondance des jetons composés dans des tableaux
- Définir des balises RegEx
- Les chaînes littérales entre guillemets
- Les quantificateurs d'expressions (facultatif). Pour de plus amples informations sur les quantificateurs d'expressions, voir Commandes de la section de règles et Quantificateurs d'expression : Comportement Avide, Réticent et Possessif.
- D'autres indicateurs divers servant au regroupement, aux commentaires et aux attributions (facultatif). Pour de plus amples informations sur les expressions regroupées, voir Opérateur de groupement ( ).
Les variables de règle dans votre grammaire de parsing forment une structure d'arbre à plusieurs niveaux avec la séquence de caractères ou avec des jetons dans un modèle de domaine. Par exemple, vous pouvez créer une grammaire de parsing définissant un modèle de domaine basé sur des données d'entrée de nom contenant les jetons <FirstName>, <MiddleName> et <LastName>.
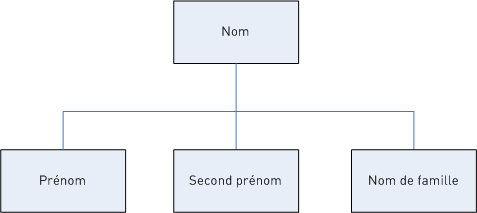
Utiliser les données d'entrée :
Joseph Arnold Cowers Vous pouvez représenter cette chaîne de données comme trois jetons dans un modèle de domaine :
<root> = <FirstName><MiddleName><LastName>; Les variables de règle pour ce modèle de domaine sont :
<FirstName> = <given>;
<MiddleName> = <given>;
<LastName> = @Table("Family Names");
<given> = @RegEx("[A-Za-z]+"); En se basant sur cette exemple de grammaire simple, l'Open Parser segmente à la hauteur des espaces et interprète le jeton Joseph comme étant un prénom, car les caractères dans ce premier jeton correspondent à la définition [A-Za- z]+ et que le jeton est dans la séquence définie. Facultativement, toute expression peut être suivie par une autre.
Exemple
<variable> = "some leading string" <variable2>;
<variable2> = @Table ("given") @RegEx("[0-9]+");
Une règle de grammaire est une phrase grammaticale où une variable est égale à une ou plusieurs expressions. Chaque règle de grammaire suit la forme suivante :
<rule> =
expression [| expression...];
Les règles de grammaire doivent suivre les règles suivantes :
<root>est un nom de variable spécial et la première règle exécutée dans la grammaire, car il définit le modèle du domaine.<root>peut ne pas être référencé par une autre règle de la grammaire.- Une variable
<rule>ne peut pas se référer à elle même de manière directe ou indirecte. Lorsque la règle A se réfère à la règle B, qui se réfère à la règle C, qui se réfère à la règle A, cela crée une référence circulaire. Les références circulaires ne sont pas autorisées. - Une variable
<rule>est égale à une ou plusieurs expressions. - Chaque
expressionest séparée par un OR, qui est indiqué par le caractère de la barre verticale (|). - Les expressions sont examinées l'une après l'autre. La première
expressionà mettre en correspondance est sélectionnée. Aucune autre expression ne sera examinée. - Le nom de la variable peut être composé de caractères alphabétiques, numériques, de tiret bas (_) et de tirets (-). Le nom de la variable peut commencer par tout caractère valide. Si le nom du champ de sortie spécifié ne respecte pas cette forme, utilisez la fonctionnalité alias pour attribuer le nom de variable au champ de sortie.
Il existe plusieurs types d'expression :
- Autre variable
- Chaîne se composant d'un ou de plusieurs caractères entre guillemets ou entre apostrophes. Par exemple :
"McDonald" 'McDonald' "O'Hara" 'O\'Hara' 'D"har' "D\"har" - Table
- CompoundTable
- Commandes RegEx