Options
- Dans Enterprise Designer, double-cliquez sur le stage Write to Search Index sur le canevas.
- Saisissez le Nom de l'index.
-
Sélectionnez un Mode d'écriture. Lorsque vous régénérez un index, vous disposez d'options liées à la manière dont les nouvelles données doivent affecter les données existantes.
- Create or Overwrite : les nouvelles données remplaceront les données existantes et celles-ci ne figureront plus dans l'index.
- Update or Append : les nouvelles données remplaceront les données existantes et toute nouvelle donnée qui n'existait pas auparavant sera ajoutée à l'index.
- Append : les nouvelles données seront ajoutées aux données existantes et celles-ci resteront intactes.
- Delete : les données du champ sélectionné seront supprimées de l'index de recherche.
-
Sélectionnez le Champ clé en fonction duquel vous souhaitez effectuer des opérations Update or Append ou Delete sur les enregistrements.
- En mode Create ou Overwrite, le Champ clé doit être unique pour les index de recherche Elastic (utilisés dans un environnement distribué). Si vous laissez le champ vide, tous les enregistrements sont stockés dans l’index, quels que soient les doublons. Cependant, vous ne pouvez effectuer aucune opération d’écriture, telle qu'une mise à jour, une modification ou une suppression, sur cet index. Le tableau suivant explique le comportement d’indexation si le Champ clé n'est pas unique pour les index de recherche Lucene et Elastic.
Mode d'écriture Champ clé Index de recherche Lucene Index de recherche Elastic Create or Overwrite
Enregistrements doublons avec le même Champ clé Tous les enregistrements sont stockés. Remarque : Les enregistrements doublons avec le même champ clé sont écrasés dès que vous exécutez l’opération de mise à jour.Tous les enregistrements doublons avec le même champ clé sont écrasés. Mettre à jour ou ajouter Enregistrements doublons avec le même Champ clé Les doublons sont remplacés. Les doublons sont remplacés.
- En mode Create ou Overwrite, le Champ clé doit être unique pour les index de recherche Elastic (utilisés dans un environnement distribué). Si vous laissez le champ vide, tous les enregistrements sont stockés dans l’index, quels que soient les doublons. Cependant, vous ne pouvez effectuer aucune opération d’écriture, telle qu'une mise à jour, une modification ou une suppression, sur cet index. Le tableau suivant explique le comportement d’indexation si le Champ clé n'est pas unique pour les index de recherche Lucene et Elastic.
- Cochez la case Validation par lot si vous souhaitez indiquer le nombre d'enregistrements à valider dans un lot lors de la création de l'index de recherche. Saisissez ensuite ce nombre dans le champ Taille de lot. La valeur par défaut est 5000.
-
Sélectionnez un Outil d'analyse pour créer les éléments suivants :
- Standard : fournit un segmenteur basé sur la grammaire qui contient un super ensemble d'analyseurs d'espace et de mot d'arrêt. Comprend la ponctuation anglaise pour segmenter les mots, connaît les mots à ignorer (via l'analyseur de mot d'arrêt), et effectue une recherche techniquement insensible à la casse en procédant à des comparaisons de minuscules. Par exemple, la chaîne « Pitney Bowes Software » serait renvoyée sous forme de trois jetons : « pitney », « bowes » et « software ». Pour une comparaison entre les analyseurs standard et de mots clés, reportez-vous à la section Analyseurs standard et de mots clés.
- Espace : sépare les jetons par des espaces. Sorte de sous-ensemble de l'analyseur standard dans la mesure où il comprend les segmentations de mots en anglais, en fonction des espaces et des retours à la ligne.
- Mot d'arrêt : supprime les articles, tels que "the," "and" et "a" pour réduire la taille de index et augmenter les performances.
- Mot clé : crée un jeton unique à partir d'un flux de données et le conserve tel quel. Par exemple, la chaîne « Pitney Bowes Software » serait renvoyée sous forme d'un jeton : « Pitney Bowes Software ». Pour une comparaison entre les analyseurs standard et de mots clés, reportez-vous à la section Analyseurs standard et de mots clés.
- Russe : prend en charge les index et les services de saisie anticipée en langue russe. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « et », « je » et « vous » pour réduire la taille de l'index et améliorer les performances.
- Allemand : prend en charge les index et les services de saisie anticipée en langue allemande. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Danois : prend en charge les index et les services de saisie anticipée en langue danoise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « à », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Néerlandais : prend en charge les index et les services de saisie anticipée en langue néerlandaise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Finnois : prend en charge les index et les services de saisie anticipée en langue finnoise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « est », « et » et « de » pour réduire la taille de l'index et améliorer les performances.
- Français : prend en charge les index et les services de saisie anticipée en langue française. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Hongrois : prend en charge les index et les services de saisie anticipée en langue hongroise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Italien : prend en charge les index et les services de saisie anticipée en langue italienne. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Norvégien : prend en charge les index et les services de saisie anticipée en langue norvégienne. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Portugais : prend en charge les index et les services de saisie anticipée en langue portugaise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Espagnol : prend en charge les index et les services de saisie anticipée en langue espagnole. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Suédois : prend en charge les index et les services de saisie anticipée en langue suédoise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Hindi : prend en charge les index et les services de saisie anticipée en langue hindi. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « par », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
-
Pour recharger le schéma à partir du serveur, cliquez sur Recharger le schéma.
Remarque : Vous pouvez modifier le nom du champ en saisissant le nouveau nom directement dans la colonne Champs. Cependant, vous ne pouvez pas modifier le nom Champs de stage, ni le Type.
- Pour ajouter/supprimer des champs de votre source d’entrée de manière sélective, cliquez sur Ajout rapide. La fenêtre contextuelle Ajout rapide affiche une liste de tous les champs de la source d’entrée. Sélectionnez les champs que vous souhaitez ajouter et cliquez sur OK.
- Sélectionnez le(s) champ(s) dont vous souhaitez stocker les données. Par exemple, à l'aide d'un fichier d'entrée d'adresses, vous pouvez indexer uniquement le code postal et choisir de stocker les champs restants (tels que Address Line 1, City, State), de telle sorte que l'ensemble de l'adresse soit renvoyé lorsqu'une correspondance est détectée via la recherche d'index.
-
Sélectionnez le(s) champ(s) dont vous souhaitez ajouter les données à l'index pour une requête de recherche.
Remarque : Si vous voulez supprimer certains champs, sélectionnez-les et cliquez sur Supprimer.
- Si nécessaire, modifiez l'analyseur pour tout champ censé utiliser autre chose que ce que vous avez sélectionné dans le champ Analyzer.
- Cliquez sur OK.
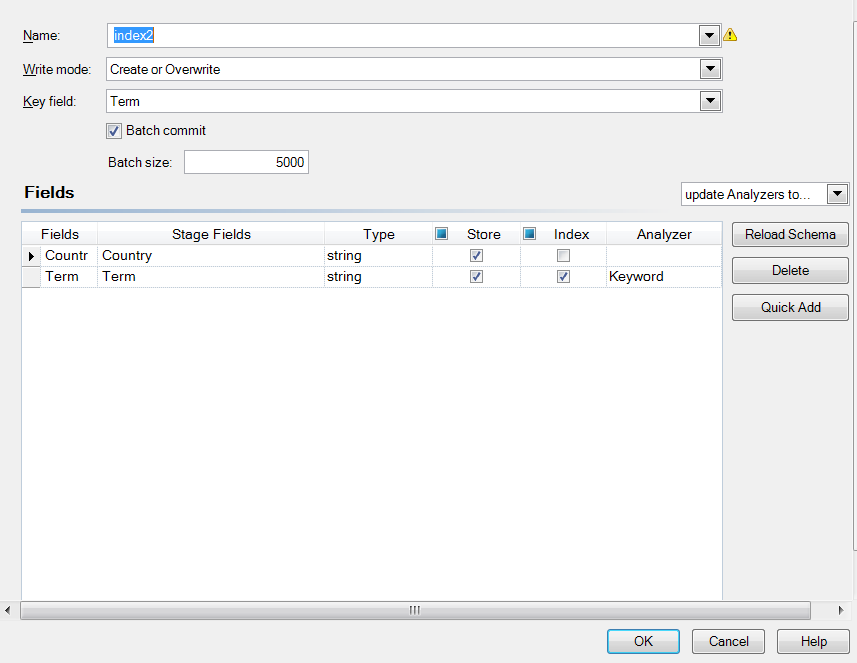
L'écran ci-dessous affiche un exemple du stage Write to Search Index Options terminé :
- U nom « SearchIndex »
- Mode Create ou Overwrite Write
- Une taille de validation de lot de 2 000 enregistrements
- L'utilisation de l'analyseur standard
- Une liste des champs figurant dans le fichier d'entrée
- Une liste des champs qui seront enregistrés avec es données d'index. Dans notre exemple, seul AddressLine2 ne sera pas enregistré.
- Une liste de champs qui composent l'index. Dans notre exemple, seul AddressLine2 n'est pas indexé.
- L'utilisateur de l'analyseur Mot clé pour le champ PostalCode