|
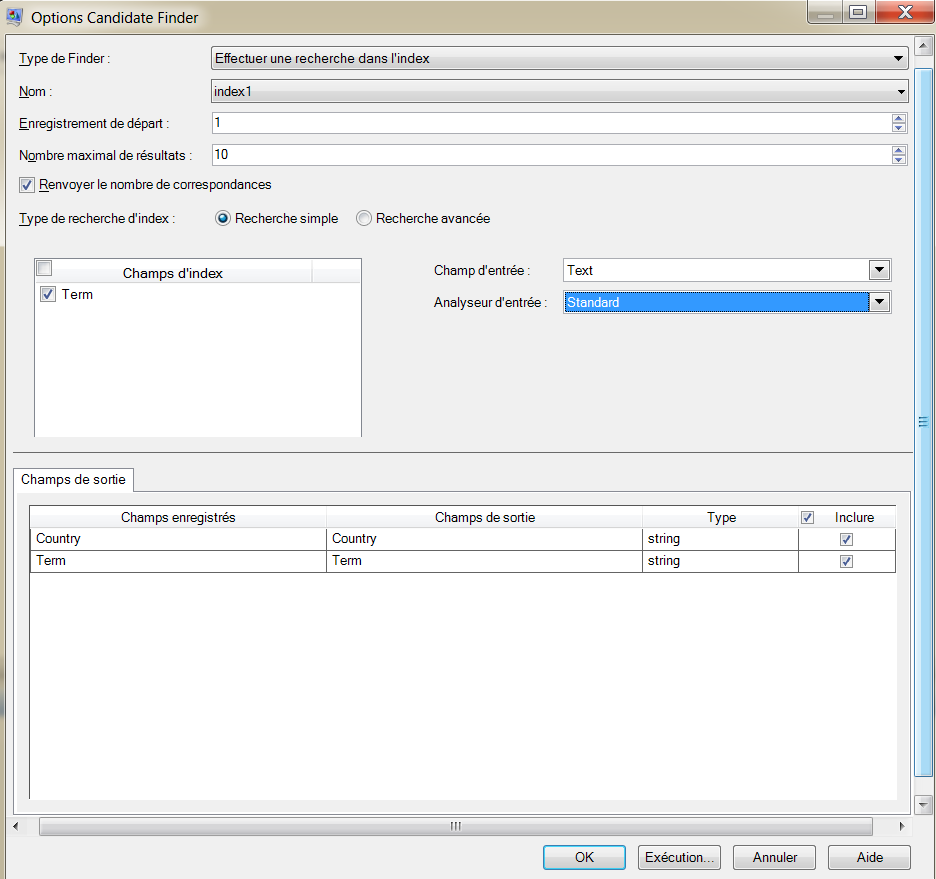
Type de Finder
|
Sélectionnez l'index de recherche.
|
|
Nom
|
Sélectionnez l'index approprié ayant été créé via le stage Write to Search Index sous les stages déployés Advanced Matching dans Enterprise Designer.
|
|
Enregistrement de départ
|
Saisissez le numéro d'enregistrement à partir duquel doivent commencer les résultats de recherche. La valeur par défaut est 1.
|
|
Nombre maximal de résultats
|
Saisissez le nombre maximal de réponses que l'index de recherche doit renvoyer. La valeur par défaut est 10.
|
|
Renvoyer le nombre total de correspondances
|
Renvoie le nombre total de correspondances effectuées. Par exemple, si vous utilisez la valeur par défaut « 10 » pour le champ Nombre maximal de résultats ci-dessus, seuls 10 résultats seront renvoyés. En revanche, si vous cochez cette case, le champ de sortie TotalMatchCount vous indique le nombre de correspondances effectuées lors du traitement.
|
| Type de recherche d'index |
Détermine le type de recherche d'index que vous souhaitez effectuer. Sélectionnez recherche Simple. |
|
|
Sélectionnez les champs d'index que vous souhaitez utiliser pour la comparaison de la recherche simple.
|
|
Champ de saisie
|
Sélectionnez le champ d'entrée que vous souhaitez utiliser pour la comparaison de la recherche simple.
|
|
Analyseur d'entrée :
|
Indiquez quel l'analyseur à utiliser pour segmenter la chaîne d'entrée. L'un des éléments suivants :
- Standard : fournit un segmenteur basé sur la grammaire qui contient un super ensemble d'analyseurs d'espace et de mot d'arrêt. Comprend la ponctuation anglaise pour segmenter les mots, connaît les mots à ignorer (via l'analyseur de mot d'arrêt), et effectue une recherche techniquement insensible à la casse en procédant à des comparaisons de minuscules. Par exemple, la chaîne « Pitney Bowes Software » serait renvoyée sous forme de trois jetons : « Pitney », « Bowes » et « Software ».
- Espace : sépare les jetons par des espaces. Sorte de sous-ensemble de l'analyseur standard dans la mesure où il comprend les segmentations de mots en anglais, en fonction des espaces et des retours à la ligne.
- Mot d'arrêt : supprime les articles, tels que "the," "and" et "a" pour réduire la taille de index et augmenter les performances.
- Mot clé : crée un jeton unique pour un flux de données. Par exemple, la chaîne « Pitney Bowes Software » serait renvoyée sous forme d'un jeton : « Pitney Bowes Software ».
- Russe : prend en charge les index et les services de saisie anticipée en langue russe. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « et », « je » et « vous » pour réduire la taille de l'index et améliorer les performances.
- Allemand : prend en charge les index et les services de saisie anticipée en langue allemande. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Danois : prend en charge les index et les services de saisie anticipée en langue danoise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « à », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Néerlandais : prend en charge les index et les services de saisie anticipée en langue néerlandaise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Finnois : prend en charge les index et les services de saisie anticipée en langue finnoise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « est », « et » et « de » pour réduire la taille de l'index et améliorer les performances.
- Français : prend en charge les index et les services de saisie anticipée en langue française. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Hongrois : prend en charge les index et les services de saisie anticipée en langue hongroise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Italien : prend en charge les index et les services de saisie anticipée en langue italienne. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Norvégien : prend en charge les index et les services de saisie anticipée en langue norvégienne. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Portugais : prend en charge les index et les services de saisie anticipée en langue portugaise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Espagnol : prend en charge les index et les services de saisie anticipée en langue espagnole. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Suédois : prend en charge les index et les services de saisie anticipée en langue suédoise. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « le », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
- Hindi : prend en charge les index et les services de saisie anticipée en langue hindi. Prend également en charge de nombreux mots d'arrêt et supprime les articles tels que « par », « et » et « un » pour réduire la taille de l'index et améliorer les performances.
|
|
Onglet Champs de sortie
|
Cochez la case Inclure pour sélectionner les champs à inclure dans la sortie. Remarque : Si le champ d'entrée provient d'un stage précédent dans le flux de données et qu'il porte le même nom que le le champ enregistré de l'index de recherche, les valeurs du champ d'entrée écraseront les valeurs dans le champ de sortie.
|