Installieren eines Clusters mit separater Konfigurationsdatenbank
Diese Prozedur erstellt zwei Cluster: eins für die Serverknoten und eins für die Konfigurationsdatenbankknoten. Die Knoten im Servercluster verweisen für ihre Konfigurationsdaten auf die Server im Konfigurationsdatenbankcluster. Die Knoten im Konfigurationsdatenbankcluster replizieren ihre Daten untereinander.
Im folgenden Diagramm wird dieses Installationsszenario veranschaulicht:
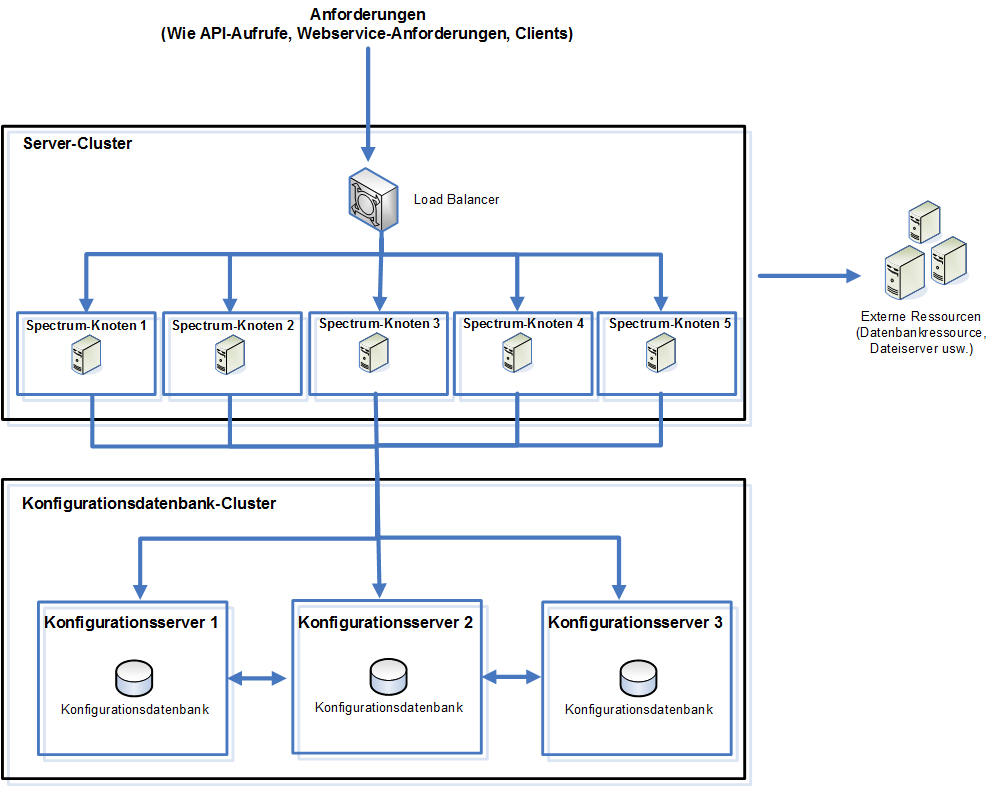
Um eine separate Datenbank zu installieren, installieren Sie zuerst die Konfigurationsdatenbank auf Servern in einem Cluster, installieren Sie dann den Server auf Knoten in einem separaten Cluster. Mindestens eine Konfigurationsdatenbank muss ausgeführt werden, bevor Sie den Server installieren können.
- Legen Sie das Spectrum™ Technology Platform-Installationsprogramm auf dem Server ab, auf dem Sie die Konfigurationsdatenbank installieren möchten.
- Führen Sie installdb.sh aus.
- Folgen Sie den Anweisungen, um die Konfigurationsdatenbank zu installieren.
- Bearbeiten Sie die Datei Database/repository/spectrum-container.properties, wie unter Clustereigenschaften für ein Konfigurationsdatenbankcluster beschrieben.
- Speichern Sie spectrum-container.properties und schließen Sie die Datei.
-
Starten Sie die Konfigurationsdatenbank. Um die Konfigurationsdatenbank zu starten, ändern Sie das Arbeitsverzeichnis in das Verzeichnis bin des Spectrum™ Technology Platform-Servers, beziehen Sie die Einrichtungsdatei und geben Sie dann den folgenden Befehl ein:
./server.start. - Installieren Sie die Konfigurationsdatenbank nach Bedarf auf zusätzlichen Servern, um das Konfigurationsdatenbankcluster zu vervollständigen.
-
Installieren Sie das Servercluster.
-
Installieren Sie Spectrum™ Technology Platform auf einem Server, auf dem Sie einen Knoten hosten möchten. Anweisungen dazu finden Sie unter Installieren eines neuen Servers.
Wichtig: Wählen Sie bei der Installation der einzelnen Server im Installationsprogramm die Option Nur Server aus, und geben Sie Host und Port von einem oder mehreren der Konfigurationsdatenbankserver an. Sie finden den Port in der Datei InstallationLocation\Database\repository\spectrum-container.properties. Der Port ist in der Eigenschaft spectrum.repository.server.connector.bolt.port angegeben.
-
Beenden Sie den Spectrum™ Technology Platform-Server, wenn er ausgeführt wird. Ändern Sie zum Beenden des Servers das Arbeitsverzeichnis in das Verzeichnis bin des Spectrum™ Technology Platform-Servers um, suchen Sie die Setup-Datei und geben Sie anschließend den folgenden Befehl ein:
./server.stop. - Bearbeiten Sie die Eigenschaften in der Datei server/app/conf/spectrum-container.properties, wie unter Clustereigenschaften beschrieben.
- Speichern und schließen Sie die Datei spectrum-container.properties.
-
Einige Module verfügen über modulspezifische Einstellungen, die Sie konfigurieren müssen, damit die Module in einem Cluster funktionsfähig sind.
Moduls Cluster-Konfigurationseinstellungen Advanced Matching-Modul Mit den folgenden Einstellungen wird das Clustering für Indizes für die Volltextsuche konfiguriert. Wenn Sie keine Indizes für die Volltextsuche verwenden, müssen Sie diese Einstellungen nicht konfigurieren. Öffnen Sie die folgende Datei in einem Texteditor:
SpectrumFolder\server\modules\searchindex\es-container.properties
Konfigurieren Sie die folgenden Eigenschaften:
- es.index.default_number_of_replicas
- Geben Sie die Anzahl zusätzlicher Kopien ein, die für jeden Suchindex erstellt werden sollen. Diese Zahl sollte der Anzahl der Knoten in Ihrem Cluster abzüglich 1 entsprechen. Wenn Ihr Cluster beispielsweise über fünf Knoten verfügt, geben Sie bei dieser Eigenschaft „4“ ein.
- es.index.default_number_of_shards
- Geben Sie die Anzahl der Shards ein, die in Ihrem Index in der verteilten Umgebung enthalten sein sollen. Je mehr Knoten in Ihrem Cluster vorhanden sind, desto höher sollte diese Zahl sein.
Speichern und schließen Sie es-container.properties, wenn Sie mit der Bearbeitung dieser Eigenschaften fertig sind.
Anmerkung: Clustering wird von Suchindizes unterstützt, die vor Spectrum™ Technology Platform 10.0 erstellt wurden. Um Clustering für Indizes zu aktivieren, die vor Version 10.0 erstellt wurden, müssen Sie den Suchindex über die 10.0-API neu erstellen, nachdem Sie die Datei es-container.properties geändert haben.Data Hub-Modul Öffnen Sie die folgende Datei in einem Texteditor: SpectrumFolder\server\modules\hub\hub.properties
Konfigurieren Sie die folgenden Eigenschaften:
- hub.models.path.base
- Gibt den Ordner an, in dem Modelle gespeichert werden. Die einzelnen Modelle werden standardmäßig in einem Unterverzeichnis unter dem Ordner SpectrumFolder\server\modules\hub\db platziert. Wenn Sie Modelle an einem anderen Speicherort speichern möchten, entfernen Sie bei dieser Eigenschaft die Kommentarzeichen und geben Sie den Ordner an, in dem Sie die Modelle speichern möchten.
- hub.neo4j.database.type
- Ändern Sie den Wert dieser Eigenschaft in ha. Der Standardwert embedded ist für Installationen ohne Cluster bestimmt.
- hub.servers.per.cluster
- Entfernen Sie bei dieser Zeile die Kommentarzeichen. Legen Sie den Wert dieser Eigenschaft auf die Anzahl der Spectrum™ Technology Platform-Server im Cluster fest.
Speichern und schließen Sie hub.properties, wenn Sie mit der Bearbeitung dieser Eigenschaften fertig sind.
SpectrumFolder\server\modules\hub\db\neo4j.properties steuert, wie die Diagrammdatenbanken mithilfe von Neo4j Enterprise konfiguriert werden. Diese Datei wird als Vorlage für die einzelnen Modelle verwendet. Bei Bedarf kann jedes Modell separat konfiguriert werden, indem eine Kopie dieser Eigenschaftsdatei im Speicherverzeichnis dieses Modells platziert wird.
Machine Learning-Modul Öffnen Sie die folgende Datei in einem Texteditor: SpectrumFolder\server\modules\machinelearning/java.vmargs
Konfigurieren Sie die folgenden Eigenschaften:
- -Xmx
- Gibt die maximale Speicherzuordnung an. Empfehlung: Passen Sie die Größe des Clusters Ihres Machine Learning-Moduls so an, dass sie circa die vierfache Größe Ihrer Daten aufweist und allen Knoten dieselbe Arbeitsspeichergröße zugewiesen wird. Stellen Sie sicher, dass die Zuordnung „-Xmx“ auf keinem der Knoten den physischen Speicherplatz überschreitet, um ein Swapping zu vermeiden.
-
Starten Sie den Server. Ändern Sie zum Starten des Servers das Arbeitsverzeichnis in das Verzeichnis bin des Spectrum™ Technology Platform-Servers um, suchen Sie die Setup-Datei und geben Sie anschließend den folgenden Befehl ein:
./server.start. aus. - Wiederholen Sie diese Prozedur für die Installation zusätzlicher Knoten im Servercluster.
-
Installieren Sie Spectrum™ Technology Platform auf einem Server, auf dem Sie einen Knoten hosten möchten. Anweisungen dazu finden Sie unter Installieren eines neuen Servers.
-
Kehren Sie nach der Installation aller Knoten im Servercluster zum ersten Knoten zurück, den Sie im Servercluster installiert haben, und fügen Sie die anderen Knoten als Seed-Knoten hinzu.
- Öffnen Sie auf dem ersten installierten Knoten die Eigenschaftendatei server/app/conf/spectrum-container.properties.
- Fügen Sie in der Eigenschaft spectrum.cluster.seeds den Hostnamen oder die IP-Adresse der anderen Knoten im Cluster hinzu, und trennen Sie diese durch ein Komma.
- Speichern Sie die Datei spectrum-container.properties und schließen Sie sie. Sie müssen den Server nicht neu starten.