El procesamiento distribuido toma partes del flujo de datos y distribuye el procesamiento de esas partes en un clúster de servidores Spectrum™ Technology Platform. Por ejemplo, es posible que su flujo de datos realice geocodificación y usted quiera distribuir el procesamiento de geocodificación entre varios nodos de un clúster Spectrum™ Technology Platform para mejorar el rendimiento.
-
Decida qué etapas de su flujo de datos quiere distribuir; luego, cree un subflujo que contenga las etapas que quiere distribuir.
No utilice las siguientes etapas en un subflujo que vaya a ser usado para el procesamiento distribuido:
- Sorter
- Unique ID Generator
- Record Joiner
- Interflow Match
Los siguientes grupos de etapas deben ser usados en el mismo subflujo para el procesamiento distribuido:
- Etapas de comparación (Intraflow Match y Transactional Match) y etapas de consolidación (Filter, Best of Breed y Duplicate Synchronization).
- Aggregator y Splitter
No incluya otros subflujos dentro del subflujo (subflujos anidados).
Deben tenerse en cuenta las siguientes consideraciones para realizar comparaciones en un subflujo utilizado para procesamiento distribuido:
- La ordenación debe realizarse en el proceso principal y no en el subflujo. Debe desactivarse la ordenación en la etapa y realizar la ordenación a nivel de proceso principal.
- El subflujo distribuido no admite análisis de coincidencias.
- Los números de colección se reutilizarán dentro de un grupo de lotes de microflujo.
El uso de una etapa Write Exception en un subflujo podría producir resultados inesperados. En su lugar, debe agregar esta etapa a su flujo de datos a nivel de trabajo.
-
Cuando haya creado el subflujo para la porción del flujo de datos que desea distribuir, agregue el subflujo al flujo de datos principal y conéctelo a una etapa de carga y descarga de datos. Los subflujos usados para el procesamiento distribuido pueden tener solo un puerto de entrada.
-
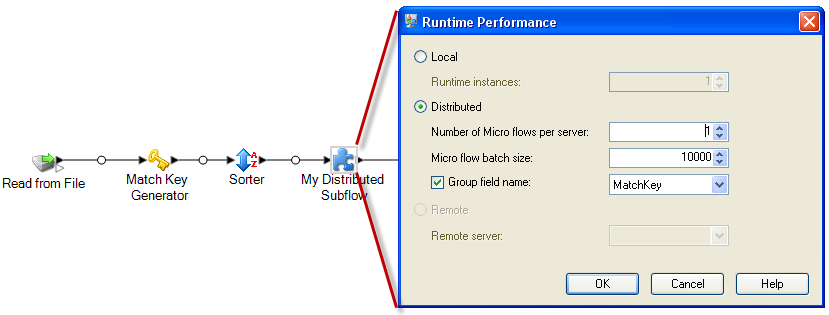
Haga clic con el botón derecho en el subflujo y seleccione Opciones.
-
Seleccione Distribuido.
-
Ingrese el número de micro flujos que se enviarán a cada servidor.
-
Ingrese el número de registros que debe haber en cada lote de micro flujos.
- Opcional:
(Opcional) Seleccione el nombre del campo Grupo y seleccione el nombre del campo según el cual deben agruparse los lotes de micro flujos.
Si proporciona un campo de grupo, el tamaño de los lotes podría ser mayor que el número que especificó en el campo Tamaño de lote de micro flujos porque un grupo no se dividirá entre múltiples lotes. Por ejemplo, si especifica que el tamaño de lote es 100, pero tiene 108 registros dentro del mismo grupo, ese lote incluirá los 108 registros. Al igual que, si especifica que el tamaño de lote es 100 y un nuevo grupo de 28 registros con la misma ID comienza en el registro 80, tendrá 108 registros en ese lote.
El ejemplo a continuación muestra un flujo de datos en el que se ha configurado un subflujo llamado "Mi subflujo distribuido" para que se ejecute de modo distribuido: