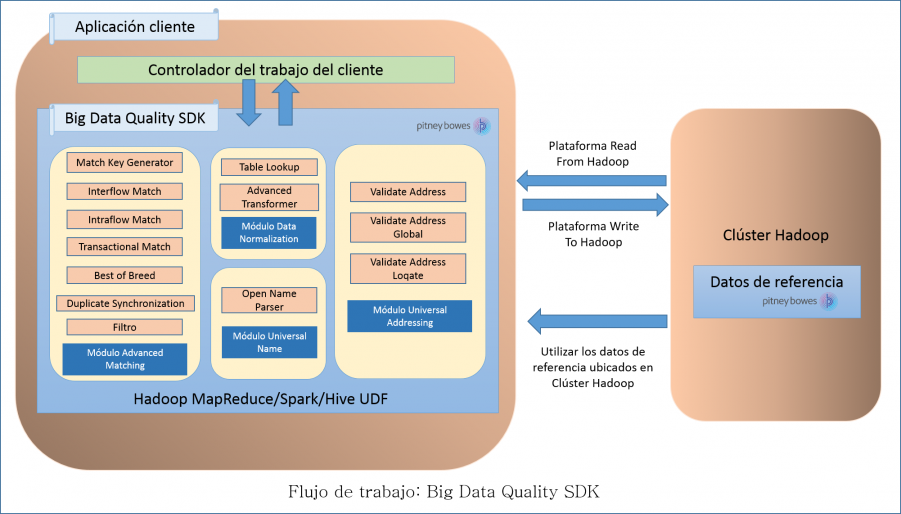
Flujo de trabajo
Para usar el SDK, los componentes necesarios son:
- instalación de Big Data Quality SDK.
- El archivo JAR Big Data Quality SDKdebe estar instalado en su sistema y disponible para que la aplicación lo utilice.
- Aplicación cliente
- La aplicación de Java que debe crear para invocar y ejecutar las operaciones de calidad de los datos requeridas mediante el SDK. El archivo JAR Big Data Quality SDK que debe importar en su aplicación Java.
- Plataforma Hadoop
- Durante la ejecución de un trabajo con Big Data Quality SDK, los datos primero se leen desde la plataforma Hadoop configurada y después del procesamiento pertinente, los datos de salida se escriben en la plataforma Hadoop.
Para esto, los detalles de acceso de la plataforma Hadoop deben estar configurados correctamente en su equipo. Para obtener más información, consulte Información general.
- Datos de referencia
- Los datos de referencia, requeridos por Big Data Quality SDK, se colocan en el clúster Hadoop.
- API de Java
-
Para usar la API de Java, puede optar por colocar los datos de referencia en cualquiera de las siguientes ubicaciones:
- Nodos de datos locales: los datos de referencia se colocan en todos los nodos de datos del clúster.Nota: Esta no es un método seguro.
- Hadoop Distributed File System (HDFS): Los datos de referencia se colocan en un directorio HDFS. Esto asegura que sus datos están protegidos.
- Nodos de datos locales: los datos de referencia se colocan en todos los nodos de datos del clúster.
- UDF de Hive
- Para usar las UDF de Hive, debe colocar los datos de referencia en cada nodo de datos local del clúster.
Nota: El SDK también permite un mejor rendimiento del Almacenamiento en caché distribuido.