iemodel trainAndevaluate model
El comando iemodel trainAndevaluate model evalúa y capacita nuevos modelos y modelos existentes. En el caso de los modelos existentes, debe sobrescribirlos con los modelos recién capacitados, y para hacerlo debe usar "true" para el argumento --u del comando.
Este comando invoca su archivo de opciones de capacitación y ofrece un archivo de salida opcional con resultados de evaluaciones, en caso de que opte por producir ese archivo.
Uso
iemodel trainAndevaluate model --f trainingOptionsFile --u trueOrFalse --o outputFileName --c categoryCount --d trueOrfalse| Requerido | Argumento | Descripción |
|---|---|---|
| Sí | --f trainingOptionsFile | Especifica el nombre y la ubicación del archivo con las opciones de capacitación que se utilizan para capacitar el modelo. Las rutas de acceso del directorio que especifique aquí es en relación con la ubicación donde ejecuta la Utilidad de administración. |
| No | --u overWriteIfExists | Especifica si se debe sobrescribir el modelo capacitado existente (en caso de que exista uno).
|
| No | --o outputFileName | Especifica el nombre y la ubicación del archivo de salida que guardará los resultados de la evaluación. |
| No | --c categoryCount | Especifica el número de categorías en el modelo; debe ser un valor numérico. Nota: Válido solo para el modelo de clasificación de texto.
|
| No | --d trueOrfalse | Especifica si se visualiza una tabla con análisis detallado con relación a la entidad; el valor debe ser true o false, como se muestra a continuación:
false. En la tabla Resultados de la evaluación del modelo, y en la Matriz de confusión con sus columnas, según se describe a continuación, aparecen los recuentos por entidad. Nota: Si el comando se ejecuta sin este argumento o con el valor de argumento falso, la tabla Resultados de la evaluación del modelo y la Matriz de confusión no se muestran. Solo aparecen las Estadísticas de evaluación de modelo.
|
Salida
- Estadísticas de evaluación de modelo
- La ejecución de este comando muestra las siguientes estadísticas de la evaluación en formato tabular:
- Precisión: es una medida de la exactitud. Precision define la proporción de tuplas identificadas correctamente.
- Recuperación: es una medida de integridad de los resultados. La recuperación se puede definir como una fracción de instancias relevantes que se recupera.
- Medida F1: es la medida de la exactitud de una prueba. El cálculo del puntaje de F1 considera la precisión y la recuperación de la prueba. Se puede interpretar como el promedio ponderado de precisión y recuperación, donde el puntaje de F1 alcanza el mejor valor en 1 y el peor en 0.
- Exactitud: mide el nivel de corrección de los resultados. Define la cercanía del valor medido al valor conocido.
- Resultados de evaluación de modelo
- Si el comando se ejecuta con el argumento
--d true, los recuentos de cruce de todas las entidades aparecen en formato tabular. Las columnas en la tabla son:- Recuento de entrada
- La cantidad de ocurrencias de la entidad en los datos de entrada.
- Recuento de coincidencia incorrecta
- La cantidad de veces que hubo error en el cruce de la entidad.
- Recuento de cruces
- La cantidad de veces que el cruce de la entidad se hizo correctamente.
- Matriz de confusión
- La Matriz de confusión (mostrada abajo) permite visualizar el rendimiento de un algoritmo. En esta se ilustra el rendimiento de un modelo de clasificación.
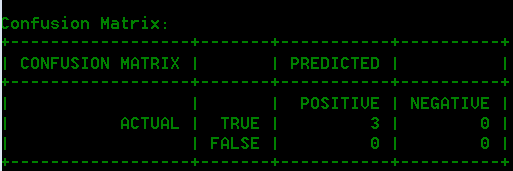
Ejemplo
Este ejemplo:
iemodel trainAndevaluate model --f C:\Spectrum\IEModels\ModelTrainingFile --u true --o C:\Spectrum\IEModels\MyModelTestOutput --c 4 --d true- Utiliza un archivo de opciones de capacitación llamado "ModelTrainingFile" que se encuentra en "C:\Spectrum\IEModels"
- Sobrescribe todo archivo de salida existente que tenga el mismo nombre
- Guarda el resultado de la evaluación en un archivo llamado "MyModelTestOutput"
- Especifica un recuento de categoría de 4
- Especifica que se requiere un análisis detallado de la evaluación.