Abflachen von HL7-Daten
HL7-Daten sind hierarchisch organisiert. Da viele Schritte die Daten in einem flachen Format benötigen, müssen Sie die Daten möglicherweise abflachen, damit die Daten in Downstream-Schrittes von Aktivitäten wie Adressenüberprüfung oder Geocoding verwendbar sind.
Die folgenden Schritte beschreiben, wie Sie einen Splitter-Schritt verwenden, um HL7-Daten abzuflachen.
-
Verbinden Sie alle Splitter-Schritte.
Sie sollten nun einen Datenfluss haben, der wie folgt aussieht:
Beispiel
Sie haben folgende HL7-Daten und möchten die Adressen im Segment PID überprüfen.
MSH|^~\&||.|||199908180016||RAS^O17|ADT.1.1698594|P|2.7
PID|1||000395122||SMITH^JOHN^D||19880517180606|M|||One Global View^^Troy^NY^12180||(630)123-4567|||S||12354768|87654321Dazu müssen Sie diese Adressdaten in flache Daten konvertieren, damit sie vom „Validate Address“-Schritt verarbeitet werden können. Sie erstellen also einen Datenfluss, der einen Splitter-Schritt gefolgt von einem „Validate Address“-Schritt enthält, was wie folgt aussehen kann:

Der Splitter-Schritt ist konfiguriert, die Nachricht bei der Komponente „PID/Patient_Address/Street_Address“ zu unterteilen und diese Daten in flache Daten zu konvertieren.
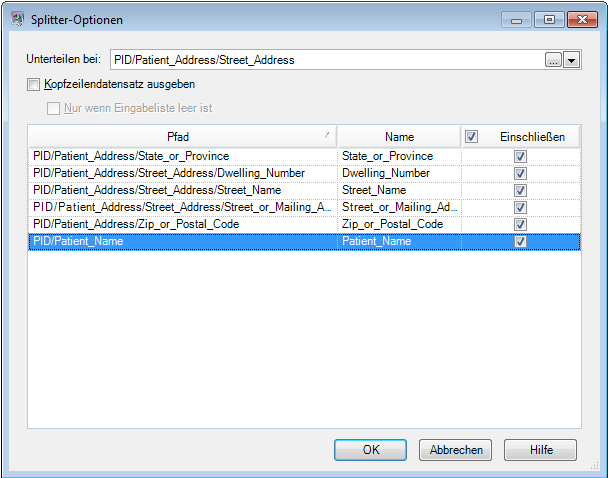
Der Kanal, der den Splitter-Schritt mit dem „Validate Address“-Schritt verbindet, benennt die Felder um, sodass die von „Validate Address“ benötigten Feldnamen verwendet werden: „Street_or_Mailing_Addres“ wird in „AddressLine1“ unbenannt, „State_or_Province“ wird in „StateProvince“ umbenannt und „Zip_or_Postal_Code“ wird in „PostalCode“ umbenannt.
In diesem Beispiel wird die Ausgabe in eine XML-Datei geschrieben, die diese Daten enthält.
<?xml version='1.0' encoding='UTF-8'?>
<XmlRoot xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<PatientInformation>
<Confidence>95</Confidence>
<RecordType>Normal</RecordType>
<CountryLevel>A</CountryLevel>
<ProcessedBy>USA</ProcessedBy>
<MatchScore>0</MatchScore>
<AddressLine1>1 Global Vw</AddressLine1>
<City>Troy</City>
<StateProvince>NY</StateProvince>
<PostalCode>12180-8371</PostalCode>
<PostalCode.Base>12180</PostalCode.Base>
<PostalCode.AddOn>8371</PostalCode.AddOn>
<Country>United States Of America</Country>
<Patient_Name>
<Family_Name>
<Surname>SMITH</Surname>
</Family_Name>
<Given_Name>JOHN</Given_Name>
<Second_and_Further_Given_Names_or_Initials_Thereof>
D
</Second_and_Further_Given_Names_or_Initials_Thereof>
</Patient_Name>
</PatientInformation>
</XmlRoot>