分散処理
非常に複雑なジョブが存在する場合や、かなり大規模なデータ セット (何百万というレコードを含むものなど) を処理する場合は、1 台以上の物理サーバー上で Spectrum™ Technology Platform サーバーの複数のインスタンスにデータフローの処理を分散させることでデータフローのパフォーマンスを向上できる可能性があります。
クラスタ環境のセットアップが完了したら、複数のサーバーに分散させるデータフローの各パーツに対するサブフローを作成することで、分散処理をデータフロー内に組み込むことができます。サブフローに対していくつかの設定オプションを指定した後は、Spectrum™ Technology Platform で自動的に処理の分散が管理されます。
次の図は、分散処理を表したものです。
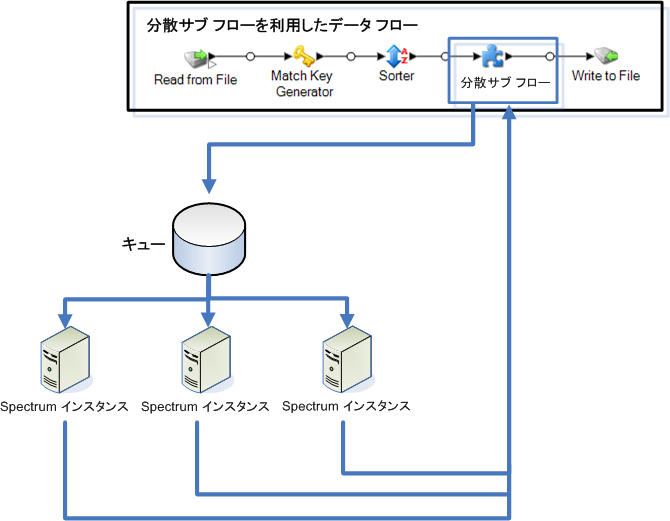
レコードがサブフロー内に読み込まれると、そのデータが各バッチにグループ化されます。その後、これらのバッチはクラスタに書き込まれ、バッチを処理するクラスタ内のノードに自動的に配布されます。この処理をマイクロフローと呼びます。サブフローは、複数のマイクロフローを同時に処理して、データフローのパフォーマンスを潜在的に向上させるように設定できます。分散インスタンスは、マイクロフローの処理を終了すると、その出力を親のデータフローに送り返します。
Spectrum™ Technology Platform のノード数が多いほど、同時に処理できるマイクロフロー数が増加するので、要求されるパフォーマンスを取得するために必要に応じて環境のスケーリングが可能です。
セットアップの完了後、クラスタ環境は容易に管理できます。クラスタ内のすべてのノードが各自の設定の同期を自動的に行っており、これは Management Console を利用して適用する設定や、Enterprise Designer で設計するデータフローが自動的にすべてのインスタンスで利用できるようになることを意味するからです。