Aggregator
Aggregator は、フラット データを階層データに変換します。Aggregator は、単一のソースから入力データを取得し、指定したフィールドに基づいてデータをグループ化することによりスキーマ (データの構造的階層) を作成し、そのグループをスキーマの中に作成します。
グループ化方法
ツリーで [グループ化] を選択してから [追加] をクリックして、階層への集約のベースとして使用するフィールドを選択します。選択したフィールドに同じ値を持つレコードのデータは、単一の階層に集約されます。複数のフィールドを選択した場合は、レコードを 1 つの階層にグループ化するには、すべてのフィールドのデータが一致する必要があります。
例えば、アカウント番号でデータをグループ化する場合は、アカウント番号フィールドを選択します。アカウント番号フィールドに同じ値を持つすべての入力レコードのデータが、単一の階層レコードにグループ化されます。
出力リスト
[出力リスト] で選択したフィールドによって、Aggregator が作成する各レコードに含めるフィールドが決まります。フィールドを追加するには、[出力リスト] を選択し、[追加] をクリックして、以下のオプションのいずれかを選択します。
- 既存フィールド
- フィールドをデータフローから階層に追加する場合は、このオプションを選択します。
- 新しいデータ タイプ
- 子フィールドを追加できる親フィールドを作成する場合は、このオプションを選択します。
- テンプレート
- このオプションにより、Aggregator の出力ポートに接続されているステージのデータに基づくフィールドを追加できます。
フィールドに子フィールドを追加する場合は、[リスト] ボックスをオンにします。
[名前] テキスト ボックスにフィールドの名前を入力するか、自動的に表示された名前でよい場合はそのままにします。Aggregator ステージでは、フィールド名に無効な XML 文字を使用できないことに注意してください。使用できるのは、英数字、ピリオド (.)、アンダースコア (_)、およびハイフン (-) です。
[追加] をクリックしてフィールドを追加します。別のフィールドを指定して階層の同じレベルに追加するか、[閉じる] をクリックします。
子フィールドを既存のフィールドに追加するには、親フィールドを選択し、[追加] をクリックします。
Aggregator の例
Aggregator の機能が適用できる例としては、ストリートの住所のグループから道順を得る場合が挙げられます。始点と終点という 2 つの地点、またはルート内の複数の通過点に対し、この機能を適用できます。このような種類の機能を実行するデータフローの例を次に示します。
このデータフローは、次のように機能を実行します。
- Read from File ステージでは、ストリートの住所がフラット ファイルに格納されています。このファイルには、次のようなフィールドがあります。
- ID: ファイル内の住所を一意に識別するためのフィールドです。
- Type: 住所が差出住所と宛先住所のどちらであるかを表します。
- AddressLine1: ストリートの住所を格納します。
- LastLine: 都市、州、および郵便番号などの情報を格納します。
- Read from File ステージと Math ステージの間の Field Transform は、ID フィールドのフォーマットを string タイプから double タイプに変換します。Math ステージが、string タイプのデータを入力として受け取ることができないためです。

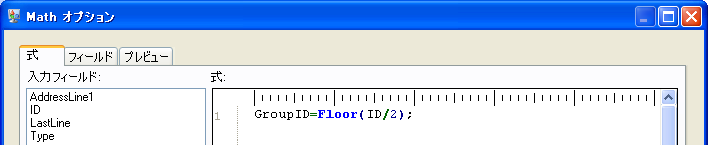
- Math ステージは、データフローの下流で使用するグループ ID (GroupID) フィールドを計算する式を作成します。この例では、ID フィールドの値を 2 で割った数以下の最大の整数、つまり小数点以下を切り捨てた数を、グループ ID とします。つまり、ID が 3 の場合、式は 3/2 となり、解は 1.5 となります。1.5 の小数点以下を切り捨てて、グループ ID は 1 となります。ID が 2 の場合は、式は 2/2、解は 1 となり、小数点以下を切り捨てる必要はありません。したがって、ID が 2 の場合も 3 の場合もグループ ID は同じ 1 になります。
- Geocode US Address は、各住所の緯度と経度を取得します。
- Aggregator ステージは、データを GroupID フィールドによってグループ化し、出力リストに緯度と経度に基づくルート ポイント (RoutePoints) が含まれるようにします。 以下に、このデータフロー用の Aggregator ステージを手動で設定する方法を示します。
- [Aggregator] ステージをダブルクリックし、[グループ化] をダブルクリックします。
- [GroupID] フィールドを選択し、[OK] をクリックします。このフィールドを使用することによって、データフローにおける次のステージのためのルート ポイントを含めることができるようになります。ルート ポイントは、データフローで道順を生成するために必須です。
- [出力リスト] をダブルクリックします。[フィールド オプション] ダイアログ ボックスが表示されます。
- [新しいデータ タイプ] を選択します。[タイプ名] フィールドで、RoutePoint と入力します。[名前] フィールドで、RoutePoints と入力します。デフォルトで、これはリストであり、変更できません。したがって、チェック ボックスは無効になっています。
- [OK] をクリックします。
- [RoutePoints] をクリックし、[追加] をクリックします。[フィールド オプション] ダイアログ ボックスが再度表示されます。
- ルート ポイントは、緯度と経度で構成されているため、まず [既存フィールド] で、既存の入力フィールド "Latitude" を追加する必要があります。[名前] フィールドの値は自動的に入力されます。
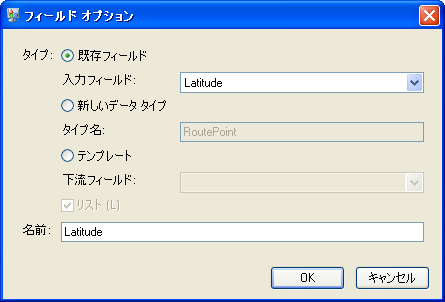
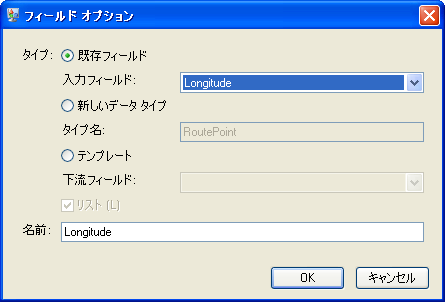
"Longitude" に対して、このステップを繰り返します。
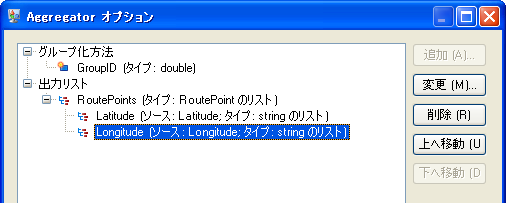
完成した Aggregator ステージは、次のように表示されます。
- Get Travel Directions は、ポイント ID 0、2、4 からポイント ID 1、3、5 までの道順をそれぞれ提供します。
- Splitter ステージでは、データを RouteDirections フィールドで分割し、出力リストに Get Travel Directions ステージから使用可能なフィールドをすべて取り込む必要があります。
- Write to File ステージでは、道順が出力ファイルに書き出されます。