Parsing de noms espagnols ou allemands
Ce modèle expose comment parser des noms de diverses cultures, comme les noms espagnols ou allemands, en éléments de composants. La règle d'analyse sépare chaque jeton du champ Nom et copie chacun dans les champs définis dans la grammaire d'analyse des noms de personnes et d'entreprises. Pour plus d'informations sur cette grammaire d'analyse, sélectionnez Outils > Open Parser Domain Editor, puis le domaine Personal and Business Names et soit la culture Allemand (de), soit la culture Espagnol (es).
Ce modèle applique aussi des codes de genre aux noms de personnes en utilisant la table de données contenue dans Table Management. Pour plus d'informations sur Table Management, sélectionnez Outils > Table Management.
Scénario commercial
Vous travaillez pour une société pharmaceutique basée à Bruxelles qui a consolidé ses opérations en Allemagne et en Espagne. Votre société désire déployer une base de données de cultures mixtes contenant des données de nom, et votre mission est d'analyser les variations de nom entre les deux cultures.
Les flux de données suivants apportent une solution au scénario commercial :
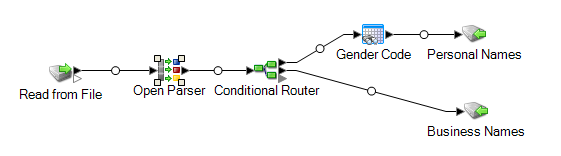
Ce modèle de flux de données est disponible dans Enterprise Designer. Accédez à et sélectionnez ParseSpanish&GermanNames. Ce flux de données requiert le module Data Normalization.
Dans ce flux de données, les données sont lues dans un fichier et traitées par le stage Open Parser. Pour chaque ligne de données dans le fichier d'entrée, ce flux de données effectuera ce qui suit :
Read from File
Ce stage identifie le nom du fichier, l'emplacement et la disposition du fichier contenant les noms que vous désirez parser. Le fichier contient à la fois des noms masculins et féminins et inclut des informations CultureCode pour chaque nom. Les informations CultureCode désignent les noms d'entrée soit allemands (de), soit espagnols (es).
Open Name Parser
Le stage Open Name Parser examine les champs de nom et les compare aux données de nom stockées dans les fichiers de la base de données de noms Spectrum™ Technology Platform. Suivant les résultats de la comparaison, il répartit les données de nom entre les champs Prénom, Deuxième prénom et Nom de famille.
Conditional Router
Ce stage route l'entrée pour que les noms de personnes soient routés vers le stage Gender Codes et que les noms commerciaux soient routés vers le stage Business Names.
Code de genre
Faites un double clic sur ce stage du canevas, puis cliquez sur Modifier pour afficher les Options de règle de Table Lookup.
L'option Catégoriser utilise la valeur Source comme clé et copie la valeur correspondante de l'entrée de table dans le champ sélectionné dans la liste Destination. Dans ce modèle, Compléter le champ est sélectionné et Source est défini de sorte à utiliser le champ FirstName. Table Lookup considère le champ entier comme une seule chaîne et marque l'enregistrement si la chaîne peut être catégorisée dans son entier.
Destination est défini sur le champ GenderCode et utilise les termes de recherche contenus dans la table Code sexe pour catégoriser les noms masculins et féminins. Si un terme ne se trouve pas dans les données d'entrée, Table Lookup assigne une valeur U, qui signifie inconnu. Pour mieux comprendre comment cela fonctionne, sélectionnez Outils > Gestion des tables, puis la table Code sexe.
Write to File
Le modèle contient deux stages Write to File, l'un pour les noms de personnes et l'autre pour les noms d'entreprises. Outre le champ d'entrée, le fichier de sortie des noms de personnes contient les champs Name, TitleOfRespect,FirstName, MiddleName, LastName, PaternalLastName, MaternalLastName, MaturitySuffix, GenderCode, CultureUsed et ParserScore.
Le fichier de sortie des noms d'entreprises, quant à lui, contient les champs Name, FirmName, FirmSuffix, CulureUsed et ParserScore.