Parsing d'adresses de courrier électronique
Ce modèle expose comment parser des adresses de courrier électronique en composants. La règle d'analyse sépare chaque jeton du champ E-mail et copie chacun dans trois champs :Local-Part, DomainName et DomainExtension. Local-Part représente la partie nom de domaine de l'adresse électronique, DomainName représente le nom de domaine de l'adresse électronique et DomainExtension représente l'extension de domaine de l'adresse électronique. Par exemple, dans pb.com,« pb » est le nom de domaine et « com » est l'extension de domaine.
Internet est une grande source d'informations du domaine public qui peut vous aider dans vos opérations d'open parsing. Dans cet exemple, les informations de formatage de courrier électronique ont été obtenues par diverses ressources Internet et ont été ensuite importées dans Table Management pour créer une table de valeurs de domaine. L'opération d'extension de domaine que vous réaliserez dans ce modèle expose l'utilité de cette méthode.
Ce modèle démontre également comment utiliser efficacement une table de données que vous chargez dans Table Management pour effectuer des recherches de table dans vos opérations de parsing.
Scénario commercial
Vous travaillez pour une compagnie d'assurance qui désire faire sa première campagne commerciale par courrier électronique. Votre base de données contient les adresses électroniques de vos clients et on vous a demandé de trouver le moyen de vous assurer que ces adresses électroniques ont un format SMTP valide.
Avant de créer ce flux de données, vous devrez charger une table d'extensions de noms de domaine valides dans Table Management pour pouvoir y consulter les extensions de noms de domaine faisant partie du processus de validation.
Les flux de données suivants apportent une solution au scénario commercial :
Ce modèle de flux de données est disponible dans Enterprise Designer. Accédez à et sélectionnez ParseEmail. Ce flux de données requiert le module Data Normalization.
Dans ce flux de données, les données sont lues dans un fichier et traitées par le stage Open Parser. Pour chaque ligne de données du fichier d'entrée, ce flux de données effectue les opérations suivantes :
Créer une table d'extension de domaine
La première opération est de créer une table Open Parser dans Table Management que vous pourrez utiliser pour vérifier si les extensions de domaine de vos adresses électronique sont valides.
- Dans le menu Outils, sélectionnez Gestion des tables.
- Dans la liste Type, sélectionnez Open Parser.
- Cliquez sur Nouveau.
- Dans la boîte de dialogue Ajouter une table définie par l'utilisateur, saisissez EmailDomains dans le champ Table Name, vérifiez que None est sélectionné dans la liste Copier à partir de, puis cliquez sur OK.
- Lorsque EmailDomains apparaît dans la liste Nom, cliquez sur Importer.
- Dans la boîte de dialogue Importer, cliquez sur Parcourir et recherchez le fichier source de la table. Son emplacement par défaut est le suivant :
<drive>:\Program Files\Pitney Bowes\Spectrum\server\modules\coretemplates\data\ Email_Domains.txt. Table Management affiche un aperçu des termes contenus dans le fichier d'importation. - Cliquez sur OK. Table Management importe les fichiers sources et affiche une liste d'extensions de domaine Internet.
- Cliquez sur Fermer. La table EmailDomains est créée. Créez maintenant le flux de données à l'aide du modèle ParseEmail.
Read from File
Ce stage identifie le nom de fichier, l'emplacement et la disposition du fichier contenant les adresses électroniques que vous souhaitez analyser.
Open Parser
La grammaire de parsing du stage Open Parser définit les commandes et expressions suivantes :
%Tokenizeest défini sur None. LorsqueTokenizeest défini surNone, la règle de grammaire de parsing doit comprendre tout espace ou autre séparateur de jetons dans sa définition.%InputFieldest défini de sorte à analyser les données d'entrée du champ Email_Address.%OutputFieldsest défini de sorte à copier les données analysées dans trois champs : Local-Part, DomainName et DomainExtension.- L'expression racine définit le modèle des jetons ayant été parsés :
<root> = <Local-Part>"@"<DomainName>"."<DomainExtension>;Les variables de règle qui définissent le domaine doivent utiliser les mêmes noms que les champs de sortis définis dans la commande OutputFields requise.
- Ce qui reste de la grammaire de parsing définit chacune des variables de règle comme des expressions.
<Local-Part> = (<alphanum> ".")* <alphanum> | (<alphanum> "_")* <alphanum> ;
<DomainName> = (<alphanum> ".")? <alphanum>;
<DomainExtension> = @Table("EmailDomains")* "."? @Table("EmailDomains");
<alphanum>=@RegEx("[A-Za-z0-9]+");
La variable <Local-Part> est définie comme une chaîne de texte contenant la variable <alphanum>, le caractère de point et une autre variable <alphanum>.
La définition de la variable <alphanum> est une expression régulière signifiant toute chaîne de caractères de A à Z, de a à a et de 0 à 9. La variable <alphanum> est utilisée tout au long de cette grammaire d'analyse et définie une seule fois sur la dernière ligne de la grammaire d'analyse.
La grammaire de parsing utilise une combinaison d'expressions régulières et de caractères libéraux pour construire un modèle pour les adresses électroniques. Tout caractère entre guillemets dans cette grammaire de parsing sont des caractères littéraux, le noms d'une table servant à la recherche, ou une expression régulière. La grammaire de parsing utilise ces caractères spéciaux :
- Le caractère « + » signifie qu'une expression régulière peut se produire une ou plusieurs fois.
- Le caractère « ? » signifie qu'une expression régulière peut se produire zéro ou une fois.
- Le caractère « | » signifie que la variable a une condition OR.
- Le caractère « ; » signifie la fin d'une règle.
Utilisez l'onglet Commandes pour explorer la signification des autres symboles spéciaux que vous pouvez utiliser dans les grammaires d'analyse en survolant la description avec la souris.
Pour tester la grammaire d'analyse, cliquez sur l'onglet Aperçu. Saisissez les adresses électroniques affichées ci-dessous dans le champ Email Address, puis cliquez sur Aperçu.
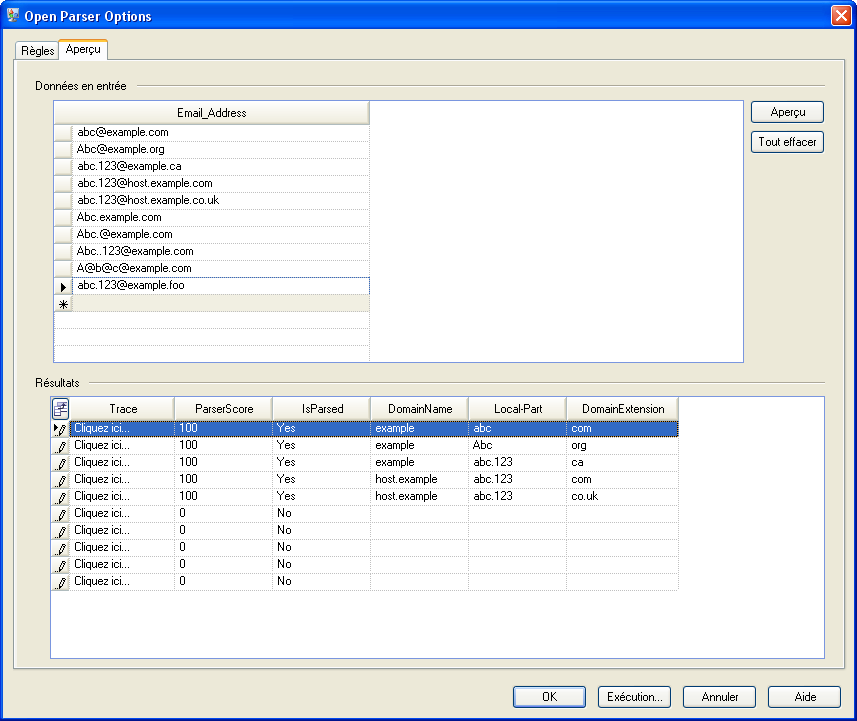
Vous pouvez aussi saisir d'autres adresses de courriel pour observer comment les données d'entrée sont parsées.
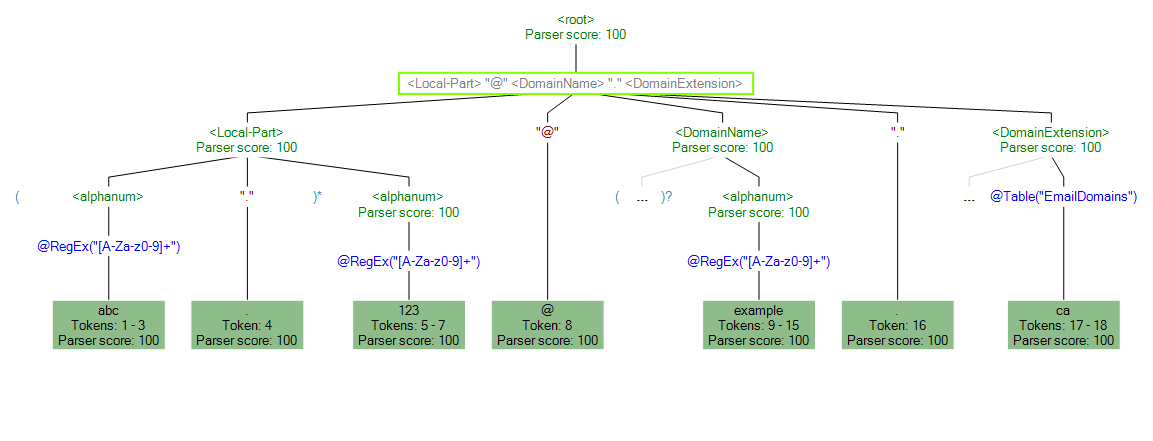
Vous pouvez aussi utiliser la fonctionnalité Suivi pour voir une représentation graphique soit du résultat de parsing final, soit étape par étape au cours des événements de parsing. Cliquez sur le lien de la colonne Suivre pour afficher Suivre les détails de la ligne de données.
Détails du suivi indique un résultat de correspondance. Comparez les jetons en correspondance pour chaque expression de la grammaire de parsing.
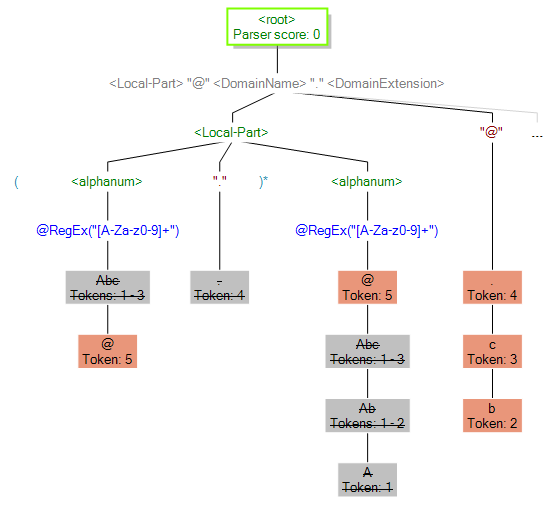
Vous pouvez aussi utiliser Aperçu pour afficher les résultats ne correspondant pas. Le graphique suivant montre un résultat non correspondant. Comparez les jetons en correspondance pour chaque expression de la grammaire de parsing. La raison pour laquelle ces données d'entrée (Abc.example.com) ne correspondaient pas est qu'elles ne contenaient pas tous les jetons requis pour correspondre : il n'existe pas de caractère @ séparant le jeton Local- Part des jetons Domain.
Write to File
Le modèle comporte un stage Write to File. Outre le champ d'entrée, le fichier de sortie contient les champs Local-Part, DomainName, DomainExtension, IsParsed et ParserScore.