Parser des noms chinois
Ce modèle expose comment parser les noms chinois en éléments de composants. La règle d'analyse sépare chaque jeton du champ Name et copie chacun dans deux champs : LastName et FirstName.
Scénario commercial
Vous travaillez pour une société de services financiers qui désire savoir s'il est possible d'inclure des caractères chinois pour ses clients de langue chinoise dans diverses correspondances.
Pour pouvoir comprendre le système des noms chinois, vous trouverez les ressources expliquant comment les noms chinois sont formés :
en.wikipedia.org/wiki/Chinese_names
Les flux de données suivants apportent une solution au scénario commercial :
Ce modèle de flux de données est disponible dans Enterprise Designer. Accédez à et sélectionnez ParseChineseNames. Ce flux de données requiert le module Data Normalization.
Dans ce flux de données, les données sont lues dans un fichier et traitées par le stage Open Parser. Pour chaque ligne de données dans le fichier d'entrée, ce flux de données effectuera ce qui suit :
Read from File
Ce stage identifie le nom du fichier, l'emplacement et la disposition du fichier contenant les noms que vous désirez parser. Le fichier contient à la fois des noms féminins et masculins.
Open Parser
Ce stage définit s'il faut utiliser une grammaire spécifique à une culture créée dans Domain Editor ou définir une grammaire indépendante du domaine. Une grammaire de parsing spécifique à une culture, que vous pouvez créer dans Domain Editor, est une grammaire de parsing validée associée à une culture et à un domaine. Une grammaire de parsing indépendante d'un domaine, que vous pouvez créer dans l'Open Parser, est une grammaire de parsing validée associée à une culture et à un domaine.
Dans ce modèle, la grammaire de parsing est définie comme grammaire indépendante du domaine.
Le stage Open Parser contient une grammaire de parsing définissant les commandes et expressions suivantes :
%Tokenizeest défini sur None. LorsqueTokenizeest défini surNone, la règle de grammaire de parsing doit comprendre tout espace ou autre séparateur de jetons dans sa définition.%InputFieldest défini de sorte à analyser les données d'entrée du champ Name.%OutputFieldsest défini de sorte à copier les données analysées dans deux champs : LastName et FirstName.
L'expression <root> définit le modèle des noms chinois :
- Une occurrence de LastName
- Une à trois occurrences de FirstName
Les variables de règle qui définissent le domaine doivent utiliser les mêmes noms que les champs de sortis définis dans la commande OutputFields requise.
La variable de règle CJKCharacter définit le modèle des caractères pour le chinois/japonais/coréen (CJK). Le modèle du caractère est défini de façon à n'utiliser que des caractères qui sont des lettres. La règle est :
<CJKCharacter> = @RegEx("([\p{InCJKUnifiedIdeographs}&&\p{L}])"); - L'expression régulière
\p{InX}sert à indiquer un bloc Unicode dans une culture donnée, oùXest la culture. Dans cette instance, la culture est CJKUnifiedIdeographs. - Dans les expressions régulières, une classe de caractères sont un ensemble de caractères que vous désirez faire correspondre. Par exemple, [aeiou] est la classe de caractères ne contenant que des voyelles. Les classes de caractères peuvent apparaître dans d'autres classes de caractères, et peuvent être composées par l'opérateur d'union (implicite) et l'opérateur d'intersection (&&). L'opérateur d'union dénote une classe contenant chaque caractère se trouvant dans au moins une des ses classes d'opérande. L'opérateur d'intersection dénote une classe contenant chaque caractère recouvrant les blocs Unicode intersectés.
- L'expression régulière
\p{L}sert à indiquer le bloc Unicode n'incluant que des lettres.
Pour tester la grammaire d'analyse, cliquez sur l'onglet Aperçu. Saisissez les noms affichés ci-dessous dans le champ Nom, puis cliquez sur Aperçu
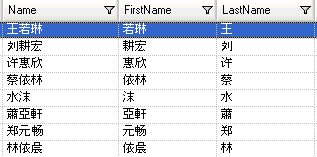
Vous pouvez aussi saisir d'autres noms valides et non valides pour observer comment les données d'entrée sont parsées.
Vous pouvez utiliser la fonctionnalité Suivi pour voir une représentation graphique soit du résultat de parsing final, soit étape par étape au cours des événements de parsing. Cliquez sur le lien de la colonne Suivre pour afficher Suivre les détails de la ligne de données.
Write to File
Le modèle comporte un stage Write to File. Outre le champ d'entrée, le fichier de sortie contient les champs LastName et FirstName Choisissez les résultats d'une correspondance depuis la Liste des résultats de correspondance et cliquez sur Supprimer.