Parser des noms arabes
Ce modèle décrit comment parser des noms arabes européanisés en éléments de composants. La règle d'analyse sépare chaque jeton du champ Nom et copie chacun dans cinq champs : Kunya, Ism, Laqab, Nasab et Nisba. Ces champs de sortie représentent les cinq parties d'un nom arabe ; ils sont décrits dans le scénario commercial.
Scénario commercial
Vous travaillez pour une banque qui désire mieux comprendre le système des noms arabes dans un effort pour améliorer son service client avec la clientèle de langue arabe. Vous avez reçu des plaintes de clients dont les informations de facturation ne faisaient pas figurer leur nom correctement. Dans un souci de connaissance plus personnelle de ses clients, le groupe marketing pour lequel vous travaillez souhaite adopter une meilleure approche de ses clients de langue arabe par le biais de campagnes marketing et d'une assistance téléphonique.
Pour pouvoir comprendre le système des noms arabes, vous trouverez les ressources expliquant comment les noms arabes sont formés sur Internet :
Les noms arabes sont basés sur un système de nommage qui inclut les cinq parties de nom suivantes : Ism, Kunya, Nasab, Laqab et Nisba.
- Ism est le nom principal, ou nom personnel d'une personne arabe.
- Souvent, kunya se rapportant au premier fils de la personne est utilisé à la place de ism.
- Nasab est un patronyme, ou une série de patronymes. Il indique le rang de naissance de la personne par le mot ibn ou bin, qui signifie fils de, et bint, qui signifie fille de.
- Laqab s'entend comme une description de la personne. Par exemple, al-Rashid signifie le vertueux ou celui qui est guidé vers le droit chemin, et al-Jamil signifie le magnifique.
- Nisba décrit l'activité d'une personne, sa zone géographique de résidence, ou son ascendance (tribu, famille, et ainsi de suite). Il suit une famille sur plusieurs générations. Nisba, parmi les composants d'un nom arabe, est peut-être celui qui s'approche le plus d'un nom de famille Européen. Par exemple, al-Filistin signifie le palestinien.
Les flux de données suivants apportent une solution au scénario commercial :
Ce modèle de flux de données est disponible dans Enterprise Designer. Accédez à et sélectionnez ParseArabicNames. Ce flux de données requiert le module Data Normalization.
Dans ce flux de données, les données sont lues dans un fichier et traitées par le stage Open Parser. Pour chaque ligne de données du fichier d'entrée, ce flux de données effectue les opérations suivantes :
Read from File
Ce stage identifie le nom du fichier, l'emplacement et la disposition du fichier contenant les noms que vous désirez parser. Le fichier contient à la fois des noms féminins et masculins.
Open Parser
Ce stage définit s'il faut utiliser une grammaire spécifique à une culture créée dans Domain Editor ou définir une grammaire indépendante du domaine. Une grammaire de parsing spécifique à une culture, que vous pouvez créer dans Domain Editor, est une grammaire de parsing validée associée à une culture et à un domaine. Une grammaire de parsing indépendante d'un domaine, que vous pouvez créer dans l'Open Parser, est une grammaire de parsing validée associée à une culture et à un domaine.
Dans ce modèle, la grammaire de parsing est définie comme grammaire indépendante du domaine.
Le stage Open Parser contient une grammaire de parsing définissant les commandes et expressions suivantes :
%Tokenizeest défini sur le caractère d'espace (\s). Cela signifie que Open Parser utilisera le caractère espace pour séparer les champs d'entrée en jetons. Par exemple, Abu Mohammed al-Rahim ibn Salamah contient cinq jetons : Abu, Mohammed, al-Rahim, ibn et Salamah.%InputFieldest défini de sorte à analyser les données d'entrée du champ Name.%OutputFieldsest défini de sorte à copier les données analysées dans cinq champs : Kunya, Ism, Laqab, Nasab et Nisba.- L'expression
<root>définit le modèle des noms arabes : - Zéro ou une occurrence de Kunya
- Exactement une ou deux occurrences de Ism
- Zéro ou une occurrence de Laqab
- Zéro ou une occurrence de Nasab
- Zéro ou plusieurs occurrences de Nisba
Les variables de règle qui définissent le domaine doivent utiliser les mêmes noms que les champs de sortis définis dans la commande OutputFields requise.
La grammaire de parsing utilise une combinaison d'expressions régulières et d'expressions de quantificateurs pour construire un modèle pour les noms arabes. La grammaire de parsing utilise ces caractères spéciaux :
- Le caractère « ? » signifie qu'une expression régulière peut se produire zéro ou une fois.
- Le caractère « * » signifie qu'une expression régulière peut se produire zéro fois ou plus.
- Le caractère « ; » signifie la fin d'une règle.
Utilisez l'onglet Commandes pour explorer la signification des autres symboles spéciaux que vous pouvez utiliser dans les grammaires d'analyse en survolant la description avec la souris.
Les quantificateurs sont avides par défaut. Avide signifie que l'expression accepte le plus grand nombre possible de jetons tout en autorisant une mise en correspondance valide. Vous pouvez outrepasser ce comportement en attachant un « ? » pour la mise en correspondance réticente ou un « + » pour la mise en correspondance possessive. Réticent signifie que l'expression accepte le moins de jetons possibles tout en autorisant une mise en correspondance valide. Possessif signifie que l'expression accepte le plus grand nombre de jetons possibles, même si cela empêche une mise en correspondance.
Pour tester la grammaire d'analyse, cliquez sur l'onglet Aperçu. Saisissez les noms affichés ci-dessous dans le champ Nom, puis cliquez sur Aperçu
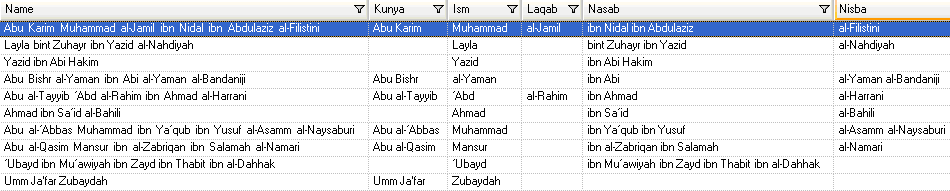
Vous pouvez aussi saisir d'autres noms valides et non valides pour observer comment les données d'entrée sont parsées.
Vous pouvez utiliser la fonctionnalité Suivi pour voir une représentation graphique soit du résultat de parsing final, soit étape par étape au cours des événements de parsing. Cliquez sur le lien de la colonne Suivre pour afficher Suivre les détails de la ligne de données.
Write to File
Le modèle comporte un stage Write to File. Outre le champ d'entrée, le fichier de sortie contient les champs Kunya, Ism, Laqab, Nasab et Nisba.