Formalisation des noms de personnes
Ce modèle de flux de données montre comment prendre des données de nom de personne (par exemple, « John P. Smith »), identifier les surnoms courants d'un même nom et créer une version standard du nom qui peut alors être utilisée pour consolider les enregistrements redondants. Il vous indique également comment ajouter les données de civilité en fonction des données de sexe.
Scénario commercial
Vous travaillez pour une organisation à but non lucratif qui désire envoyer des invitations pour un gala. Vos données d'entrée comprennent des données de nom comme des noms complets et vous désirez parser les données de nom en champs de prénom et de nom de famille, et ajouter un titre de respect pour rendre vos invitations plus formelles. Vous voulez aussi remplacer tous les surnoms de vos données de nom par une variante du nom plus formelle.
Les flux de données suivants apportent une solution au scénario commercial :
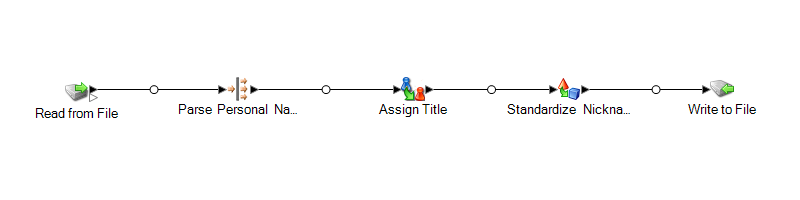
Ce modèle de flux de données est disponible dans Enterprise Designer. Accédez à et sélectionnez StandardizePersonalNames. Ce flux de données requiert les modules Data Normalization et Universal Name.
Pour chaque ligne de données dans le fichier d'entrée, ce flux de données effectuera ce qui suit :
Read from File
Ce stage identifie le nom du fichier, l'emplacement et la disposition du fichier contenant les noms que vous désirez parser. Le fichier contient à la fois des noms féminins et masculins.
Name Parser
Dans ce modèle, le stage Parser les noms de personne est nommée Parse Personal Name. Le stage Parse Personal Name examine les champs de noms et les compare aux données de noms stockées dans les fichiers de la base de données de noms Spectrum™ Technology Platform. En se basant sur la comparaison, il parse les données de noms en champs de prénom, second prénom et nom de famille, et assigne à chaque nom un type d'entité et un genre. Il utilise aussi une reconnaissance de modèle en plus des données de nom.
Dans ce modèle, le stage Parser les noms de personne est configurée comme suit.
- Le parsing des noms de personnes est sélectionné et le parsing des noms commerciaux est effacé. Lorsque vous sélectionnez ces options, les prénoms sont évalués afin de déterminer leur sexe, leur ordre et leur ponctuation et aucune évaluation de noms d'entreprises n'est réalisée.
- Gender Determination Source (Source de détermination du sexe) est définie par défaut. Dans la plupart des cas, le paramètre par défaut est le plus adapté à la détermination par sexe parce qu'il couvre une grande variété de noms. Toutefois, si vous traitez des noms pour une culture spécifique, sélectionnez cette culture. La sélection d'une culture spécifique aide à garantir l'assignation d'un genre approprié aux noms. Par exemple, si vous laissez la sélection par défaut, le nom de Jean sera identifié comme un prénom féminin. Par contre, si vous sélectionnez Français, il sera identifié comme un prénom masculin.
- L'ordre est paramétré sur naturel. Les champs de nom sont classés par titre, prénom, deuxième prénom, nom de famille et suffixe.
- Conserver les points est effacé. Aucune ponctuation figurant dans le nom n'est conservée.
Transformer
Dans ce modèle, le stage Transformer se nomme Assign Titles (Assigner des titres). Le stage Assign Titles utilise un script personnalisé pour effectuer une recherche sur chaque ligne du flux de données émis par le stage Parse Personal Name et assigne une valeur TitleOfRespect en fonction de la valeur GenderCode.
Le script personnalisé est :
if (row.get('TitleOfRespect') == '')
{
if (row.get('GenderCode') == 'M')
row.set('TitleOfRespect', 'Mr')
if (row.get('GenderCode') == 'F')
row.set('TitleOfRespect', 'Ms') Chaque fois que le stage Assign Titles trouve M dans le champ GenderCode, il définit la valeur de TitleOfRespect sur Mr. Chaque fois que le stage Assign Titles trouve F dans le champ GenderCode, il définit la valeur de TitleOfRespect sur Ms.
Standardisation
Dans ce modèle, le stage Standardisation se nomme Standardize Nicknames (Standardiser les surnoms). Le stage Standardize Nickname recherche les prénoms dans la base de données Nicknames.xml et remplace tous les surnoms par la forme plus réglementaire du nom. Par exemple, le nom Tommy est remplacé par Thomas.
Write to File
Le modèle comporte un stage Write to File. En plus des champs d'entrée, le fichier de sortie contient les champs TitleOfRespect, FirstName, MiddleName, LastName, EntityType, GenderCode, et GenderDeterminationSource.