Identification des membres d'un même foyer
Ce modèle de flux de données montre comment identifier les membres d'un même foyer en comparant les informations de chaque fichier d'entrée et en créant un fichier de sortie de groupes de foyers.
Scénario commercial
En tant que data steward pour une société de cartes de crédit, vous souhaitez analyser votre base de données client et déterminer les adresses doublons et leurs noms, afin de minimiser le nombre de courriers électroniques dupliqués et d'offres de carte de crédit envoyées à la même adresse.
Les flux de données suivants apportent une solution au scénario commercial :
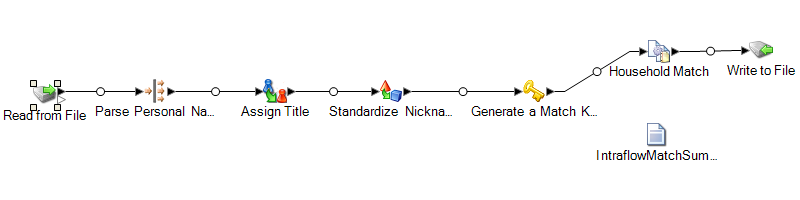
Ce modèle de flux de données est disponible dans Enterprise Designer. Accédez à et sélectionnez HouseholdRelationships. Ce flux de données requiert les modules suivants : Advanced Matching, Data Normalization et Universal Name
Pour chaque enregistrement du fichier d'entrée, ce flux de données procède comme suit :
Read from File
Ce stage identifie le nom du fichier, l'emplacement et la disposition du fichier contenant les noms que vous désirez parser. Le fichier contient à la fois des noms féminins et masculins.
Open Name Parser
Le stage Open Name Parser examine les champs de nom et les compare aux données de nom stockées dans les fichiers de la base de données de noms Spectrum™ Technology Platform. En se basant sur la comparaison, il parse les données de noms en champs de prénom, second prénom et nom de famille, et assigne à chaque nom un type d'entité et un genre. Il utilise aussi une reconnaissance de modèle en plus des données de nom.
Standardize Nicknames
Dans ce modèle, le stage Table Lookup se nomme Standardize Nicknames. Le stage Standardize Nickname recherche les prénoms dans la base de données Nicknames.xml et remplace tous les surnoms par la forme plus réglementaire du surnom. Par exemple, le nom Tommy est remplacé par Thomas.
Transformer
Dans ce modèle, le stage Transformer se nomme Assign Titles (Assigner des titres). Le stage Assign Titles utilise un script personnalisé pour effectuer une recherche sur chaque ligne du flux de données émis par le stage Parse Personal Name et assigne une valeur TitleOfRespect en fonction de la valeur GenderCode.
Le script personnalisé est :
if (row.get('TitleOfRespect') == '')
{
if (row.get('GenderCode') == 'M')
row.set('TitleOfRespect', 'Mr')
if (row.get('GenderCode') == 'F')
row.set('TitleOfRespect', 'Ms')Chaque fois que le stage Assign Titles trouve M dans le champ GenderCode, il définit la valeur de TitleOfRespect sur Mr. Chaque fois que le stage Assign Titles trouve F dans le champ GenderCode, il définit la valeur de TitleOfRespect sur Ms.
Match Key Generator
Match Key Generator traite les règles définies par l'utilisateur composées d'algorithmes et de champs de source d'entrée pour générer le champ de clé de correspondance. Une clé de correspondance est un clé non-unique partagée par des enregistrements semblables identifiant les enregistrements comme des doublons. Les clés de correspondance servent à faciliter le processus de correspondance simplement en comparant des enregistrements contenant la même clé de correspondance. Une match key se compose de champs d'entrée. Un algorithme sélectionné s'applique sur chaque champ d'entrée indiqué. Le résultat de chaque champ est ensuite concaténé pour créer un seul champ de clé de correspondance.
Dans ce modèle, deux champs clés de correspondance sont définis : SubString (LastName (1:3)) et SubString (PostalCode (1:5)).
Par exemple, si l'adresse entrante était :
FirstName - Fred
LastName - Mertz
PostalCode - 21114-1687
Et les règles spécifiaient que :
|
Champ de saisie |
Position de début |
Longueur |
|---|---|---|
|
LastName |
1 |
3 |
|
PostalCode |
1 |
5 |
Alors la clé, basée sur les règles et les données d'entrée indiquées plus haut, serait :
Mer21114
Household Match
Dans ce modèle de flux de données, le stage Intraflow Match est appelé Household Match. Ce stage repère les correspondances entre des enregistrements de données similaires à l'intérieur d'un seul flux d'entrée. Des enregistrements correspondants peuvent aussi être qualifiés à l'aide d'informations ne se rapportant ni à un nom ni à une adresse. Le moteur de correspondance vous permet de créer des règles hiérarchiques basées sur n'importe quel champ défini ou créé dans d'autres stages.
Un flux d'enregistrements devant être comparés ainsi que les paramètres spécifiant quels champs doivent être comparés, comment les scores doivent être calculés, et d'une façon plus générale tout ce qui constitue une correspondance réussie.
Dans ce modèle, créez une règle de correspondance personnalisée qui compare LastName et AddressLine1. Cochez la case Générer les données pour analyse pour générer les données pour le rapport Interflow Summary.
Il y a quelques consignes à suivre lors de la création de votre hiérarchie de correspondance :
- Un nœud parent doit recevoir un nom unique. Cela ne peut pas être un champ.
- Le champ enfant doit être un champ de type de données Spectrum™ Technology Platform, il s'agit donc d'un champ disponible via un ou plusieurs composants.
- Tous les enfants sous un parent doivent utiliser les mêmes opérateurs logiques. Pour combiner des connecteurs, vous devez d'abord créer des nœuds parents intermédiaires.
- Les seuils au nœud parent peuvent être plus élevés que le seuil de l'enfant.
- Les nœuds parent n'ont pas besoin d'avoir un seuil.
Write to File
Le modèle contient une étape Write to File qui crée un fichier texte indiquant les adresses sous forme d'un ensemble de seuils.
Rapport de synthèse intra-flux
Le modèle contient le rapport de synthèse de Intraflow Match. Après avoir exécuté la tâche, développez Rapports dans la fenêtre Détails d'exécution, puis cliquez sur IntraflowMatchSummary.
Le Rapport de synthèse de Intraflow Match liste les statistiques des enregistrements traités et affiche un graphique à barres illustrant de façon graphique le décompte des enregistrements et le score général de correspondance.