Parser des noms de personne
Si vous disposez de données de nom, figurant toutes dans un champ, il serait judicieux d'analyser le nom dans des champs distincts correspondant aux différentes parties du nom, telles que le prénom, le nom de famille, la civilité, etc. Ces éléments nom analysés peuvent ensuite être utilisés par d'autres opérations automatisées telles que le rapprochement par nom, la standardisation de noms ou la consolidation de noms enregistrés plusieurs fois.
-
Faites glisser un stage Open Name Parser sur le canevas et connectez-le au stage source.
Par exemple, si vous utilisez un stage Read from File, votre flux de données se présente comme suit :
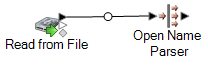
-
Faites glisser un stage de collecteur de données et connectez-le au stage Open Name Parser.
Par exemple, si vous utilisez un collecteur de données Write to File, votre flux de données se présente comme suit :
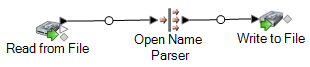
Vous avez créé un flux de données capable d'analyser les noms personnels en des parties de composant, plaçant chaque partie du nom dans son propre champ.