Présentation de l'analyse
L'analyse est le processus consistant à analyser une séquence de caractères d'entrée dans un champ et à la diviser en plusieurs champs. Par exemple, vous pouvez disposer d'un champ appelé Nom qui contient la valeur « John A. Smith » et, grâce à l'analyse, vous pouvez le diviser afin d'obtenir un champ Prénom contenant « John », un champ Deuxième prénom contenant « A » et un champ Nom de famille contenant « Smith ».
Pour créer un flux de données qui effectue l'analyse, utilisez le stage Open Parser. Open Parser vous permet d'écrire les règles d'analyse appelées grammaires. Une grammaire est un ensemble d'expressions qui mappent une séquence dans un ensemble d'entités nommées appelé modèles de domaine. Un modèle de domaine est une séquence d'un ou plusieurs jetons dans vos données d'entrée que vous souhaitez représenter par une structure de données, tels qu'un nom, une adresse ou des numéros de compte. Un modèle de domaine peut être composé de n'importe quel nombre de jetons pouvant être analysés depuis vos données d'entrée. Un modèle de domaine est représenté dans la grammaire de parsing comme l’expression <root>. Les données d'entrée contiennent souvent ce type de jetons sous un format difficile à utiliser ou un format mixte. Par exemple :
- Vos données d'entrée contiennent des noms dans un seul champ que vous souhaitez séparer en des prénoms et des noms de famille.
- Vos données d'entrée contiennent des adresses provenant de plusieurs cultures et vous souhaitez extraire les données d'adresse uniquement pour une culture spécifique.
- Vos données d'entrée comprennent du texte en forme libre contenant des adresses électroniques intégrées et vous souhaitez extraire les adresses électroniques et les mettre en correspondance avec des données personnelles et les stocker dans une base de données.
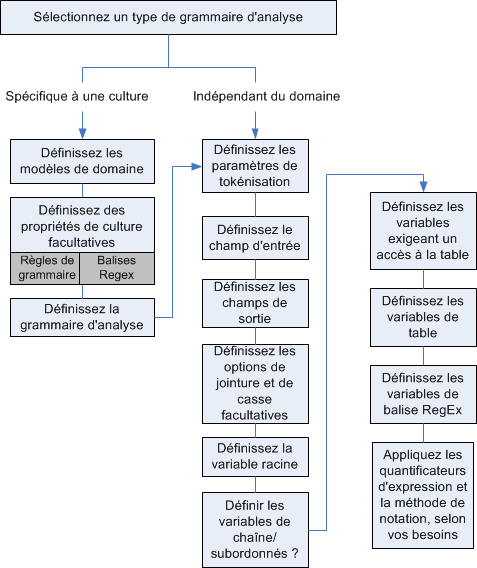
Il existe deux types de grammaires : propre à la culture et indépendante au domaine. Une grammaire d'analyse propre à la culture est associée à une culture et/ou à une langue (telle que l'anglais, l'anglais canadien, l'espagnol, l'espagnol mexicain, etc.) et à un type particulier de données (numéros de téléphone, noms personnels, etc.). Lorsqu'un stage Open Parser est configuré pour effectuer une analyse propre à la culture, la grammaire d'analyse de chaque culture s'applique à tous les enregistrements. La grammaire dotée du meilleur score d'analyse (ou la première atteignant un score de 100) est celle dont les résultats sont renvoyés. Sinon, les grammaires d'analyse propres à la culture peuvent utiliser la valeur dans le champ CultureCode de l'enregistrement d'entrée et traiter les données en fonction des paramètres de la culture contenus dans la grammaire d'analyse de la culture. Les grammaires de parsing spécifiques à une culture peuvent hériter des propriétés d'un parent. Une grammaire d'analyse indépendante du domaine n'est pas associée à une langue ou à un type particulier de données. Les grammaires de parsing indépendantes d'un domaine n'héritent pas des propriétés d'un parent et ignorent toute information de CultureCode des données d'entrée.
Open Parser analyse une séquence de caractères dans les champs d'entrée et les catégorise dans un séquence de jetons via un processus appelé segmentation. La segmentation consiste à délimiter et à classifier les sections d'une chaîne de caractères d'entrée en un ensemble de jetons par marquage des caractères (également appelé caractères de segmentation), par exemple, un espace, un trait d'union, etc. Les jetons sont ensuite placés dans les champs de sortie que vous indiquez.
Le schéma suivant illustre la procédure de création d'une grammaire d'analyse :