Análisis de direcciones de correo electrónico
Esta plantilla muestra cómo dividir las direcciones de correo electrónico en las partes que la componen. La regla de análisis separa cada muestra del campoCorreo electrónico y copia las distintas muestras a tres campos: Parte local, Nombre de dominio y extensión del dominio. Parte local representa la parte del nombre del dominio de la dirección de correo electrónico, Nombre de dominio representa el nombre del dominio de la dirección de correo electrónico y Extensión del dominio representa la extensión del dominio de la dirección de correo electrónico. Por ejemplo, en pb.com, "pb" es el nombre de dominio y "com" es la extensión de dominio.
Internet es una gran fuente de información de dominio público que puede ayudarlo en sus tareas de análisis abierto. En este ejemplo, la información de formato de correo electrónico se obtuvo a través de varios recursos de Internet y luego se importó en Administración de tablas para crear una tabla de valores de dominio. La tarea de extensión de dominio que se realiza en esta actividad de plantilla muestra la utilidad de este método.
Esta plantilla también muestra cómo utilizar de forma efectiva los datos de las tablas que se cargan en Administración de tablas para realizar búsquedas en ellas como parte de las tareas de análisis.
Situación empresarial posible
Usted trabaja para una compañía de seguros que quiere realizar su primera campaña de marketing por correo electrónico. Su base de datos contiene direcciones de correo electrónico de sus clientes y se le ha solicitado buscar la forma de asegurarse de que esas direcciones de correo electrónico tengan un formato SMTP válido.
Antes de crear este flujo de datos, es necesario cargar una tabla con extensiones de nombres de dominio válidos en Administración de tablas para poder buscar las extensiones del nombre de dominio como parte del proceso de validación.
El siguiente flujo de datos ofrece una solución ante una posible situación empresarial:
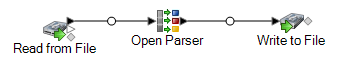
Esta plantilla de flujo de datos está disponible en Enterprise Designer. Vaya a y seleccione Analizar correo electrónico. Este flujo de datos requiere el módulo Data Normalization.
En este flujo de datos, los datos se leen desde un archivo y se procesan mediante la etapa Open Parser (Analizador abierto). Para cada fila de datos del archivo de entrada, este flujo de datos hará lo siguiente:
Creación de una tabla de extensiones de dominio
La primera tarea es crear una tabla Open Parser en Administración de tareas que pueda usarse para controlar si las extensiones de dominio en sus direcciones de correo electrónico son válidas.
- En el menú Herramientas, seleccione Administración de tablas.
- En la lista Tipo, seleccione Open Parser.
- Haga clic en Nuevo.
- En el cuadro de diálogo Agregar tabla definida por el usuario, ingrese EmailDomains en el campo Nombre de tabla; asegúrese de que esté seleccionado Ninguna esté seleccionada en la lista Copiar desde y después haga clic en Aceptar.
- Estando mostrado Dominios de correo electrónico en la lista Nombre, haga clic en Importar.
- En el cuadro de diálogo Importar, haga clic enExaminar y ubique el archivo fuente de la tabla. La ubicación predeterminada es:
<drive>:\Program Files\Pitney Bowes\Spectrum\server\modules\coretemplates\data\ Email_Domains.txt. Administración de tablas muestra una vista previa de los términos que se encuentran en el archivo de importación. - Haga clic en Aceptar. Administración de tablas importa los archivos fuente y muestra una lista de extensiones de dominio de Internet.
- Haga clic en Cerrar. Se crea la tabla EmailDomains. Luego, cree el flujo de datos utilizando la plantilla ParseEmail.
Read from File
Esta etapa Read from File identifica el nombre, la ubicación y el diseño del archivo que contiene las direcciones de correo electrónico que desea analizar.
Open Parser
La gramática de análisis de la etapa Open Parser (Analizador abierto) define los siguientes comandos y expresiones:
%Tokenizeestá configurado en Ninguno. Cuando se defineTokenizeenNone, la regla gramatical de análisis debe incluir todos los espacios u otros separadores de muestra al interior de su definición de regla.%InputFieldestá configurado para analizar los datos de entrada provenientes del campo Email_Address.%OutputFieldsestá configurado para copiar los datos analizados a tres campos: Local-Part, DomainName y DomainExtension.- La expresión de raíz define el patrón de muestras que se analiza:
<root> = <Local-Part>"@"<DomainName>"."<DomainExtension>;Las variables de regla que definen el dominio deben utilizar los mismos nombres que los campos de salida definidos en el comando OutputFields requerido.
- El resto de la gramática de análisis define cada una de las variables de regla como expresiones.
<Local-Part> = (<alphanum> ".")* <alphanum> | (<alphanum> "_")* <alphanum> ;
<DomainName> = (<alphanum> ".")? <alphanum>;
<DomainExtension> = @Table("EmailDomains")* "."? @Table("EmailDomains");
<alphanum>=@RegEx("[A-Za-z0-9]+");
La variable <Local-Part> está definida como una cadena de texto que contiene la variable <alphanum>, el carácter de punto y otra variable <alphanum>.
La definición de la variable <alphanum> es una expresión regular que coincide con cualquier cadena de caracteres de la A a la Z, de la "a" a la "z" y del 0 al 9. La variable <alphanum> se utiliza a lo largo de esta gramática de análisis y está definida una vez en la última línea de la gramática de análisis.
La gramática de análisis utiliza una combinación de expresiones regulares y caracteres literales para construir un patrón de direcciones de correo electrónico. Los caracteres entre comillas dobles en esta gramática de análisis son caracteres literales, el nombre de una tabla utilizada para búsquedas o una expresión regular. La gramática de análisis utiliza estos caracteres especiales:
- El carácter "+" significa que una expresión regular puede ocurrir una o más veces.
- El carácter "?" significa que una expresión regular puede ocurrir cero veces o una vez.
- El carácter "|" significa que la variable tiene una condición OR.
- El carácter ";" indica el final de una regla.
Utilice la ficha Comandos para explorar el significado del resto de los símbolos especiales que puede utilizar en las gramáticas de análisis pasando el mouse sobre la descripción.
Para probar la gramática de análisis, haga clic en la ficha Vista previa. Ingrese en el campo Dirección de correo electrónico las direcciones de correo electrónico que se muestran más adelante, y después haga clic en Vista previa.
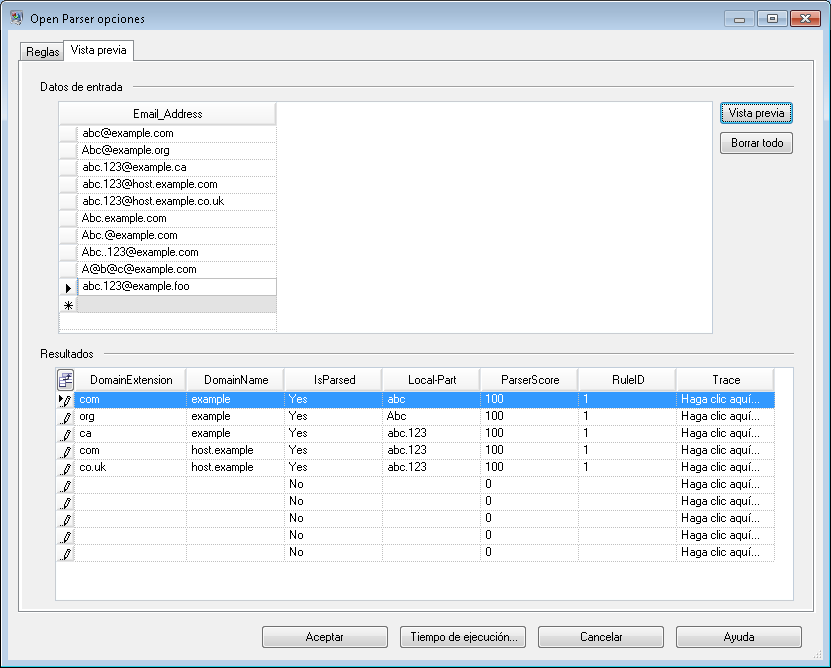
También puede ingresar otras direcciones de correo electrónico para ver cómo se analizan los datos de entrada.
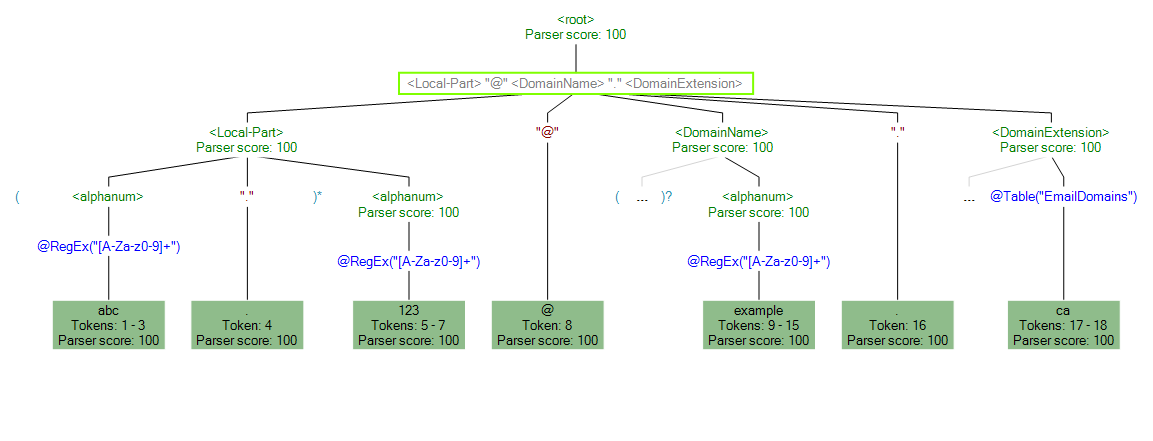
También es posible utilizar la función de seguimiento para ver una representación gráfica de los resultados finales de análisis o para recorrer los eventos de análisis. Haga clic en el enlace de la columna Seguimiento para ver los Detalles de seguimiento de la fila de datos.
En Detalles de seguimiento se muestra un resultado de comparación. Compare las muestras cruzadas de cada expresión de la gramática de análisis.
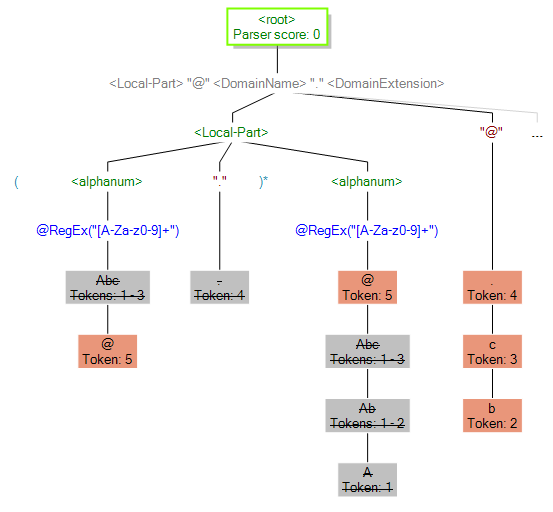
También puede utilizar la función de seguimiento para ver resultados sin coincidencias. El siguiente gráfico muestra un resultado sin coincidencias. Compare las muestras cruzadas de cada expresión de la gramática de análisis. La razón por la que estos datos de entrada (Abc.example.com) no coincidieron es que no contienen todas las muestras requeridas para el cruce: no hay un carácter @ que separe la muestra Local- Part y las muestras de dominio..
Write to File
La plantilla contiene una etapa Write to File (Escritura en archivo). Además del campo de entrada, el archivo de salida contiene los campos Parte local, Nombre de dominio, Extensión del dominio, IsParsed y ParserScore.