Análisis de nombres chinos
Esta plantilla muestra cómo dividir los nombres chinos en las partes que los componen. La regla de análisis separa cada muestra del campo Nombre y copia cada muestra a dos campos: Apellido y Primer nombre.
Situación empresarial posible
Usted trabaja para una empresa de servicios financieros que quiere explorar si es posible incluir los caracteres chinos en varias comunicaciones con los clientes que hablan chino.
Para entender el sistema de nombres chinos, hace una búsqueda y encuentra este recurso en Internet, que explica cómo están conformados los nombres chinos:
en.wikipedia.org/wiki/Chinese_names
El siguiente flujo de datos ofrece una solución ante una posible situación empresarial:
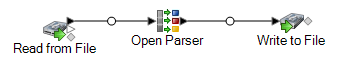
Esta plantilla de flujo de datos está disponible en Enterprise Designer. Vaya a y seleccioneAnalizar nombre chinos. Este flujo de datos requiere el módulo Data Normalization.
En este flujo de datos, los datos se leen desde un archivo y se procesan mediante la etapa Open Parser (Analizador abierto). Para cada fila de datos del archivo de entrada, este flujo de datos hará lo siguiente:
Read from File
La etapa Read from File (Lectura desde archivo) identifica el nombre, la ubicación y el diseño del archivo que contiene los nombres que desea analizar. El archivo contiene tanto nombres masculinos como femeninos.
Open Parser
La etapa Open Parser (Analizador abierto) define si se utiliza una gramática de dominio específica de una cultura creada en Domain Editor o si se define una gramática independiente de dominio. Una gramática de análisis específica de una cultura creada en Domain Editor es una gramática de análisis validada que está asociada a una cultura y un dominio. Una gramática de análisis independiente de dominio creada en Open Parser es una gramática de análisis validada que no está asociada a una cultura ni un dominio.
En esta plantilla, la gramática de análisis se define como una gramática independiente de dominio.
La etapa Open Parser contiene una gramática de análisis que define los siguientes comandos y expresiones:
%Tokenizeestá configurado en Ninguno. Cuando se defineTokenizeenNone, la regla gramatical de análisis debe incluir todos los espacios u otros separadores de muestra al interior de su definición de regla.%InputFieldestá configurado para analizar los datos de entrada provenientes del campo Nombre.%OutputFieldsestá configurado para copiar los datos analizados a dos campos: LastName y FirstName.
La expresión <root> define el patrón de los nombres chinos:
- Una ocurrencia de Apellido
- Una a tres ocurrencias de Primer nombre
Las variables de regla que definen el dominio deben utilizar los mismos nombres que los campos de salida definidos en el comando OutputFields requerido.
La variable de la regla CJKCharacter define el patrón de caracteres para chino, japonés y coreano (CJK, según la inicial en inglés de cada idioma). El patrón de caracteres está definido para utilizar solo caracteres que son letras. La regla es:
<CJKCharacter> = @RegEx("([\p{InCJKUnifiedIdeographs}&&\p{L}])"); - La expresión regular
\p{InX}se utiliza para indicar un bloque Unicode para una determinada cultura, en la queXes la cultura. En este ejemplo, la cultura es CJKUnifiedIdeographs. - En las expresiones regulares, una clase de carácter es un conjunto de caracteres que se desea cruzar. Por ejemplo, [aeiou] es la clase de carácter que contiene solo vocales. Las clases de caracteres pueden aparecer dentro de otras clases de caracteres y pueden estar compuestas por la operación de unión (implícitas) y el operador de intersección (&&). El operador de unión indica una clase que contiene cada carácter que se encuentra en al menos una de las clases de operandos. El operador de intersección indica una clase que contiene cada carácter que se superpone con los bloques Unicode intersecados.
- La expresión regular
\p{L}se utiliza para indicar el bloque Unicode que incluye solo letras.
Para probar la gramática de análisis, haga clic en la ficha Vista previa. Ingrese los nombres que se muestran más abajo en el campo Nombre y haga clic en Vista previa.
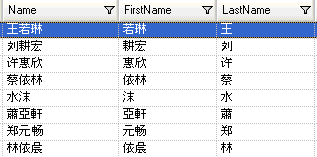
También es posible ingresar otros nombres válidos y no válidos para ver cómo se analizan los datos de entrada.
Es posible utilizar la función de seguimiento para ver una representación gráfica de los resultados finales de análisis o para recorrer los eventos de análisis. Haga clic en el enlace de la columna Seguimiento para ver los Detalles de seguimiento de la fila de datos.
Write to File
La plantilla contiene una etapa Write to File (Escritura en archivo). Además del campo de entrada, el archivo de salida contiene los campos Apellido y Primer nombre. Seleccione todos los resultados de la Lista Resultados de cruce y haga clic en Eliminar.