Análisis de nombres árabes
Esta plantilla muestra cómo dividir los nombres árabes occidentalizados en las partes que los componen. La regla de análisis separa cada muestra en el campo Nombre y copia cada muestra en cinco campos: Kunya, Ism, Laqab, Nasab, Nisba. Estos campos de salida representan las cinco partes de un nombre en árabe, que se describen en el escenario de negocios.
Situación empresarial posible
Usted trabaja para un banco que quiere entender mejor el sistema de nombres árabes a fin de mejorar el servicio de atención a los clientes que hablan árabe. Ha recibido quejas de los clientes porque la información de facturación no contiene el nombre correcto del cliente. Para mejorar la relación con el cliente, el equipo de marketing en el que trabaja quiere apelar a los clientes que hablan árabe mediante campañas de marketing y asistencia telefónica.
Para entender el sistema de nombres árabes, hace una búsqueda y encuentra los siguientes recursos en Internet que explican tal sistema:
Los nombres árabes se basan en un sistema de asignación de nombres que incluye estas piezas: Ism, Kunya, Nasab, Laqab y Nisba.
- Ism es el nombre principal, o nombre personal, de una persona árabe.
- Por lo general, kunya hace referencia al hijo primogénito y sirve de sustituto de ism.
- Nasab es un patronímico o una serie de patronímicos. Indica el legado de una persona mediante la palabra ibn o bin, que significa hijo, y bint, que significa hija.
- Laqab es una descripción de la persona. Por ejemplo, al-Rashid significa "el honrado" o "el bien guiado" y al-Jamil significa "el bello".
- Nisba describe la ocupación de la persona, el área geográfica natal o la ascendencia (tribu, familia, etc.). Acompaña a una familia a lo largo de varias generaciones. El elemento nisba, entre todos los componentes del nombre árabe, es quizá el que más se asemeja al apellido occidental. Por ejemplo, al-Filistin significa "el palestino".
El siguiente flujo de datos ofrece una solución ante una posible situación empresarial:
Esta plantilla de flujo de datos está disponible en Enterprise Designer. Vaya a y seleccione ParseArabicNames Este flujo de datos requiere el módulo Data Normalization.
En este flujo de datos, los datos se leen desde un archivo y se procesan mediante la etapa Open Parser (Analizador abierto). Para cada fila de datos del archivo de entrada, este flujo de datos hará lo siguiente:
Read from File
La etapa Read from File (Lectura desde archivo) identifica el nombre, la ubicación y el diseño del archivo que contiene los nombres que desea analizar. El archivo contiene tanto nombres masculinos como femeninos.
Open Parser
La etapa Open Parser (Analizador abierto) define si se utiliza una gramática de dominio específica de una cultura creada en Domain Editor o si se define una gramática independiente de dominio. Una gramática de análisis específica de una cultura creada en Domain Editor es una gramática de análisis validada que está asociada a una cultura y un dominio. Una gramática de análisis independiente de dominio creada en Open Parser es una gramática de análisis validada que no está asociada a una cultura ni un dominio.
En esta plantilla, la gramática de análisis se define como una gramática independiente de dominio.
La etapa Open Parser contiene una gramática de análisis que define los siguientes comandos y expresiones:
%Tokenizeestá configurado con el carácter de espacio (\s). Esto significa que Open Parser utilizará el carácter de espacio para separar el campo de entrada en muestras. Por ejemplo, Abu Mohammed al-Rahim ibn Salamah contiene cinco fichas: Abu, Mohammed, al-Rahim, ibn y Salamah.%InputFieldestá configurado para analizar los datos de entrada provenientes del campo Nombre.%OutputFieldsestá configurado para copiar datos analizados en cinco campos: Kunga, Ism, Laqab, Nasab y Nisba.- La expresión
<root>define el patrón de los nombres árabes: - Cero o una ocurrencia de Kunya
- Exactamente una o dos ocurrencias de Ism
- Cero o una ocurrencia de Laqab
- Cero o una ocurrencia de Nasab
- Cero o más ocurrencias de Nisba
Las variables de regla que definen el dominio deben utilizar los mismos nombres que los campos de salida definidos en el comando OutputFields requerido.
La gramática de análisis utiliza una combinación de expresiones regulares y cuantificadores de expresión para construir un patrón de nombres árabes. La gramática de análisis utiliza estos caracteres especiales:
- El carácter "?" significa que una expresión regular puede ocurrir cero veces o una vez.
- El carácter "*" significa que una expresión regular puede ocurrir cero o más veces.
- El carácter ";" indica el final de una regla.
Utilice la ficha Comandos para explorar el significado del resto de los símbolos especiales que puede utilizar en las gramáticas de análisis pasando el mouse sobre la descripción.
De forma predeterminada, los cuantificadores son expansivos. Se dice que son expansivos porque la expresión acepta todas las muestras posibles, pero a la vez, permite un cruce exitoso. Es posible invalidar este comportamiento agregando '?' en los cruces reacios o '+' en los cruces posesivos. Se los llama cruces reacios porque la expresión acepta la menor cantidad de muestras posibles, pero a la vez, permite un cruce exitoso. En el caso de los cruces posesivos, la expresión acepta todas las muestras posibles aunque ello impida un cruce.
Para probar la gramática de análisis, haga clic en la ficha Vista previa. Ingrese los nombres que se muestran más abajo en el campo Nombre y haga clic en Vista previa.
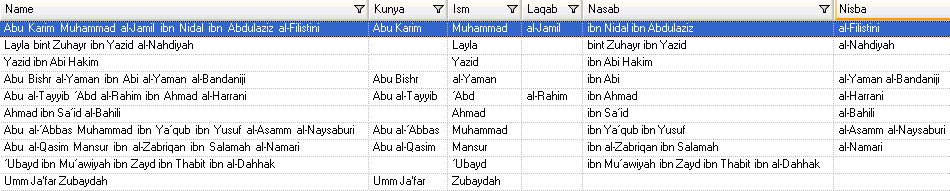
También es posible ingresar otros nombres válidos y no válidos para ver cómo se analizan los datos de entrada.
Es posible utilizar la función de seguimiento para ver una representación gráfica de los resultados finales de análisis o para recorrer los eventos de análisis. Haga clic en el enlace de la columna Seguimiento para ver los Detalles de seguimiento de la fila de datos.
Write to File
La plantilla contiene una etapa Write to File (Escritura en archivo). Además del campo de entrada, el campo de salida contiene los campos Kunya, Ism, Laqab, Nasab, y Nisba.