Comparación de registros con varias reglas de cruce
Si posee registros que desea comparar y requiere usar más de una operación de comparación, puede crear y flujo de datos que utilice más de una clave de cruce y luego combine los resultados para realizar la comparación eficazmente a partir de varios criterios independientes. Por ejemplo, imagine que desea crear un flujo de datos que compare registros donde:
Coincida el nombre y la dirección
OR
Coincida la fecha de nacimiento y la identificación emitida por el gobierno
Para realizar la comparación mediante el uso de esta lógica, debe crear un flujo de datos que realice la comparación de nombre y dirección en una etapa y la de la fecha de nacimiento y la identificación emitida por el gobierno en otra etapa y luego combinar los registros coincidentes en una sola colección.
Este tema ofrece un procedimiento general para la configuración de un flujo de datos, donde la comparación se realiza durante el transcurso de dos etapas de comparación. Este procedimiento utiliza etapas Intraflow Match para propósitos de ilustración. Sin embargo, también puede utilizar esta técnica con Interflow Match.
- Genere un nuevo flujo de datos en Enterprise Designer.
- Arrastre hacia el lienzo una etapa de origen.
- Haga doble clic en la etapa de origen y configúrela. Consulte la Guía de Dataflow Designer para obtener instrucciones acerca de cómo configurar etapas de origen.
-
Defina la primera sesión de comparación. Los resultados de esta primera sesión de comparación serán las colecciones de registros que coinciden con el primer conjunto de criterios de comparación, por ejemplo los registros que coinciden en el nombre y la dirección.
-
Arrastre una etapa Match Key Generator y una etapa Intraflow Match al lienzo y conéctelas de modo que el flujo de datos tenga la siguiente apariencia:

-
Arrastre una etapa Match Key Generator y una etapa Intraflow Match al lienzo y conéctelas de modo que el flujo de datos tenga la siguiente apariencia:
-
Guarde los números de colección de la primera etapa de comparación en otro campo. Esto es necesario ya que el campo CollectionNumber se sobrescribirá durante la segunda sesión de comparación. Se requiere cambiar el nombre del campo CollectionNumber para conservar los resultados de la primera sesión de comparación.
-
Arrastre una etapa Transformer al lienzo y conéctela a la etapa Intraflow Match, de modo que el flujo de datos con la siguiente apariencia:

-
Arrastre una etapa Transformer al lienzo y conéctela a la etapa Intraflow Match, de modo que el flujo de datos con la siguiente apariencia:
-
Defina la segunda sesión de comparación. Los resultados de esta segunda sesión de comparación serán las colecciones de registros que coinciden con el segundo conjunto de criterios de comparación, por ejemplo los registros de la fecha de nacimiento y la identificación emitida por el gobierno.
-
Arrastre una etapa Match Key Generator y una etapa Intraflow Match al lienzo y conéctelas de modo que el flujo de datos tenga la siguiente apariencia:

-
Arrastre una etapa Match Key Generator y una etapa Intraflow Match al lienzo y conéctelas de modo que el flujo de datos tenga la siguiente apariencia:
-
Determine si alguno de los registros duplicados identificados por la segunda sesión de comparación, también se identificaron como duplicados en la primera sesión de comparación.
-
Cree el fragmento de código del flujo de datos que se muestra a continuación de la segunda etapa Intraflow Match:

-
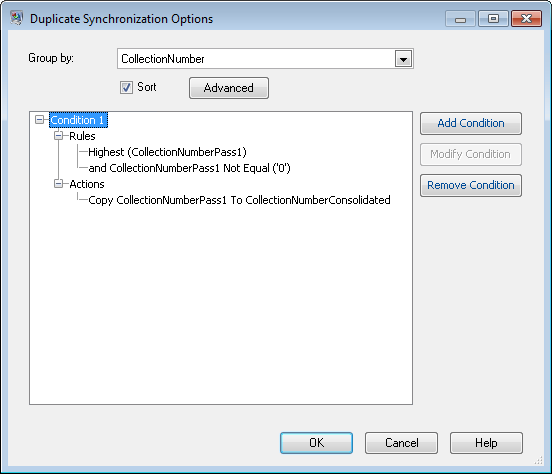
Configure la etapa Duplicate Synchronization para agrupar los registros según el campo CollectionNumer (este es el número de colección desde la segunda etapa de comparación) Luego, dentro de cada colección, identifique si alguno de los registros en la colección también se identificó como duplicado en la primera sesión de comparación. Si los hubo, copie el número de colección de la primera sesión al nuevo campo denominado CollectionNumberConsolidated. Para hacer esto, configure Duplicate Synchronization como se muestra aquí:
-
Cree el fragmento de código del flujo de datos que se muestra a continuación de la segunda etapa Intraflow Match:
- Después de Stream Combiner tendrá colecciones de registros que coinciden en cualquiera de las sesiones de comparación. El campo CollectionNumberConsolidated indica los registros coincidentes. Puede agregar un receptor o algún procesamiento adicional que desee realizar después de la etapa Stream Combiner.