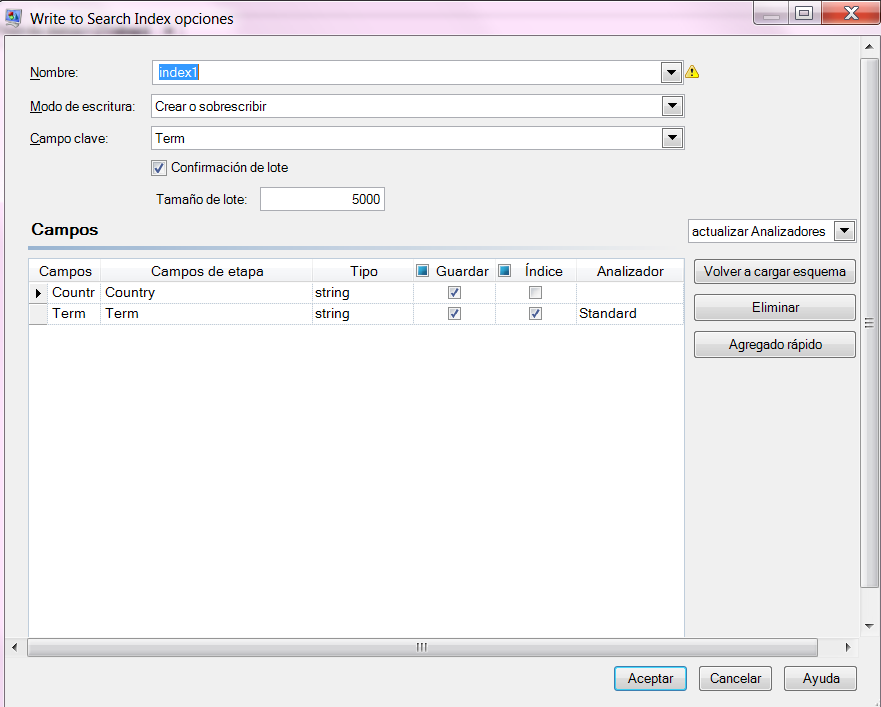
Opciones
- En Enterprise Designer, haga doble clic en el lienzo en la etapa de índice de Write to Search.
- Ingrese un nombre para la conexión.
-
Seleccione un modo de escritura. Cuando se regenera un índice, se tienen opciones relacionadas con cómo deben afectar los nuevos datos a los datos ya existentes.
- Crear o sobrescribir: los nuevos datos sobrescribirán los datos existentes y estos últimos ya no estarán en el índice.
- Actualizar o Adjuntar: los nuevos datos sobrescriben los datos existentes y todos los datos nuevos que antes no existían, se agregarán al índice.
- Adjuntar: los nuevos datos se adjuntarán a los datos existentes y estos últimos permanecerán intactos.
- Eliminar: los datos del campo seleccionado se eliminarán del índice de búsqueda.
-
Select the Key field on the basis of which you want to Update or Append or Delete the records.
- In case of Create or Overwrite mode, the Key field needs to be unique for Elastic search indexes (used in a distributed environment). If you leave the field blank, all the records get stored in the index irrespective of any duplication. However, you will not be able to perform any write operation, such as update, append, and delete on this index. The following table explains the indexing behavior if the Key field is non-unique for Lucene and Elastic search indexes.
Modo de escritura: Campo de clave Lucene search index Elastic search index Create or Overwrite
Duplicate records with same Key field All the records are stored. Nota: The duplicate records with same key field get overwritten as soon as you run the update operation.All duplicate records with the same Key field are overwritten. Actualizar o adjuntar Duplicate records with same Key field Duplicates are overwritten. Duplicates are overwritten.
- In case of Create or Overwrite mode, the Key field needs to be unique for Elastic search indexes (used in a distributed environment). If you leave the field blank, all the records get stored in the index irrespective of any duplication. However, you will not be able to perform any write operation, such as update, append, and delete on this index. The following table explains the indexing behavior if the Key field is non-unique for Lucene and Elastic search indexes.
- Marque la casilla Confirmación de lote si desea especificar el número de registros para confirmar en un lote, mientras se crea el índice de búsqueda. Luego, ingrese el número en el campo Tamaño del lote. El valor predeterminado es 5000.
-
Seleccione un analizador para construir:
- Standard: Ofrece formación de muestras basada en gramática que contiene un superconjunto de analizadores de Whitespace y Stop Word. Comprende la puntuación del español para separar las palabras, sabe qué palabras ignorar (a través de Stop Word Analyzer) y realiza búsquedas que técnicamente no distinguen entre mayúsculas y minúsculas, con comparaciones de minúsculas. Por ejemplo, la cadena de caracteres “Pitney Bowes Software” se devolvería como tres muestras: “Pitney”, “Bowes” y “Software”. For a comparison of Standard and Keyword analyzers, see Standard and Keyword Analyzer.
- Whitespace: Separa las muestras con espacios en blanco. Es un subconjunto de Standard Analyzer en cuanto comprende los espacios entre palabras en español en textos basados en espacios y saltos de línea.
- Stop Word: Elimina los artículos, como "la", "y" y "a" para reducir el tamaño del índice y aumentar el rendimiento.
- Keyword—Creates a single token from a stream of data and keeps is as is. Por ejemplo, la cadena de caracteres “Pitney Bowes Software” se devolvería como una muestra: “Pitney Bowes Software”. For a comparison of Standard and Keyword analyzers, see Standard and Keyword Analyzer.
- Ruso: admite índices de idioma ruso y servicios de avance de caracteres. También es compatible con diversas palabra no significativas y elimina artículos como "y", "yo" y "tú" para reducir el tamaño del índice y aumentar el rendimiento.
- Alemán: admite índices de idioma alemán y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Danés: admite índices de idioma danés y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "en", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Holandés: admite índices de idioma holandés y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Finlandés: admite índices de idioma finlandés y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "es", "y" y "de" para reducir el tamaño del índice y aumentar el rendimiento.
- Francés: admite índices de idioma francés y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Húngaro: admite índices de idioma húngaro y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Italiano: admite índices de idioma italiano y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Noruego: admite índices de idioma noruego y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Portugués: admite índices de idioma portugués y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Español: admite índices de idioma español y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Sueco: admite índices de idioma sueco y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "el", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
- Hindi: admite índices de idioma hindi y servicios de avance de caracteres. También es compatible con diversas palabras no significativas y elimina artículos como "por", "y" y "un" para reducir el tamaño del índice y aumentar el rendimiento.
-
To reload the schema from the server, click Reload Schema.
Nota: Puede cambiar el nombre del campo, escribiendo el nuevo nombre directamente en la columna de campos. However, you cannot change the Stage Fields name or the Type.
- To selectively add/remove fields from your input source, click Quick Add. The Quick Add pop-up window displays a list of all the fields from the input source. Select the fields that you want to add and click OK.
- Seleccione los campos de los que desea almacenar datos. Por ejemplo, si se utiliza un archivo de entrada de direcciones, puede indexar solo el campo de código postal y almacenar el resto de los campos (como la línea de dirección 1, la ciudad, el estado) para que se entregue toda la dirección cuando se encuentre una coincidencia con la búsqueda de índice.
-
Seleccione los campos de los que desea agregar datos al índice para consultas de búsqueda.
Nota: If you want to delete certain fields, select those and click Delete.
- Si fuera necesario, cambie el analizador por cualquier campo que use algo distinto a lo que haya seleccionado en el campo Analizador.
- Haga clic en Aceptar.
La pantalla que aparece a continuación muestra un ejemplo de la etapa de las opciones de índice completa de Write to Search:
- Un nombre de "SearchIndex"
- Modos de escritura Crear o Sobrescribir
- Un tamaño confirmado de lote de 2000 registros
- El uso del analizador Standard
- Una lista de los campos que componen el archivo de entrada
- Una lista de los campos que se almacenarán junto con los datos de los índices. En nuestro caso, solo AddressLine2 no se almacenará.
- Una lista de campos que componen el índice. En nuestro caso, solo AddressLine2 no se indexará.
- El uso del analizador de palabra clave para el campo PostalCode