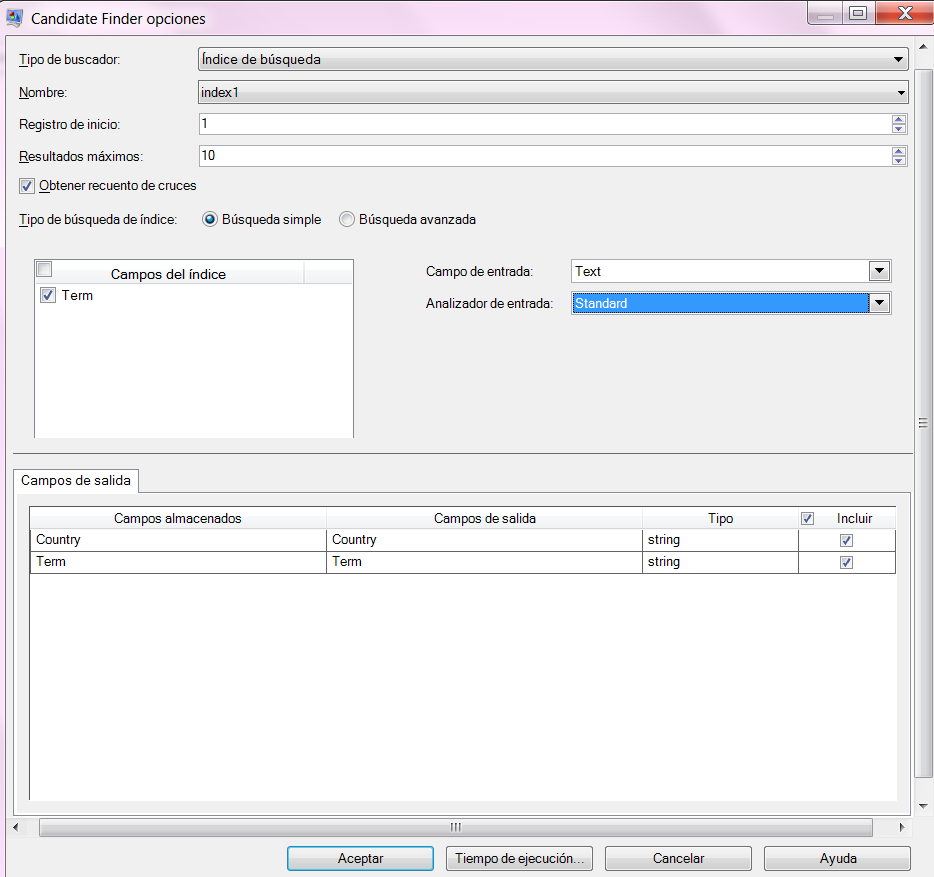
Opciones de índice de búsqueda simple
|
Nombre de la opción |
Descripción / Valores válidos |
|---|---|
|
Tipo de buscador |
Seleccione Índice de búsqueda. |
|
Nombre |
Seleccione el índice correspondiente que se creó con la etapa Write to Search Index (Escritura en índice de búsqueda) en las etapas implementadas de Advanced Matching en Enterprise Designer. |
|
Starting record (Registro de inicio) |
Ingrese el número de registro donde deben comenzar los resultados de la búsqueda. El valor predeterminado es 1. |
|
Resultados máximos |
Ingrese la cantidad máxima de respuestas que desea que arroje la búsqueda de índice. El valor predeterminado es 10. |
|
Obtener recuento de cruces |
Devuelve el número total de cruces realizados. Por ejemplo, si usa el valor predeterminado "10" para el campo Resultados máximos, solo se mostrarán 10 resultados. Sin embargo, si marca esta casilla, el campo de salida TotalMatchCount le indicará cuántos cruces se realizaron durante el procesamiento. |
| Tipo de búsqueda de índice | Determina el tipo de búsqueda de índice que desea realizar. Seleccione Búsqueda simple. |
|
Campos del índice |
Seleccione los campos de índice que desea usar para comparación en la búsqueda simple. |
|
Campo de entrada |
Seleccione el campo de entrada que desea usar para comparación en la búsqueda simple. |
|
Analizador de entrada |
Especifique el analizador que se usará para la función Tokenize en la cadena de entrada. Una de las siguientes:
|
|
Ficha Campos de salida |
Marque la casilla Incluir para seleccionar los campos almacenados que se deben incluir en el resultado.
Nota: Si el campo de salida es de una etapa anterior en el flujo de datos y posee el mismo nombre que el del campo almacenado del índice de búsqueda, los valores del campo de entrada sobrescribirán los valores en el campo de salida.
|
- Un índice de búsqueda cuyo Nombre es "CF_Index"
- Un Registro de inicio configurado en 100, lo que significa que los resultados de la búsqueda comenzarán en el registro número 100
- Resultados máximos configurado en 25, lo que significa que solo se devolverán 25 resultados
- Una opción seleccionada para Devolver recuento de coincidencias, que incluirá todos los registros, no solo los 25 a los que restringimos esta vista
- Un Tipo de búsqueda de índice simple
- Se usa un Campo de índice de ‘City’ para establecer la coincidencia con el campo de entrada 'City'
- Se usa un Campo de entrada de ‘City’ para establecer la coincidencia con el campo de índice 'City'
- Un analizador de entrada alemán para comparar campos
- Un mapa de campo que muestra que estamos devolviendo todos los campos en la salida.