Splitter
Splitter (Diviseur) convertit des données hiérarchiques en données à plat. Les Splitters disposent d'un port d'entrée et d'un port de sortie qui transmettent les données du Splitter au stage suivant. Une façon de se servir de la fonctionnalité de Splitter consiste à prendre une liste d'informations dans un fichier et extraire chaque élément d'informations discret dans sa propre ligne de données. Par exemple, votre entrée peut comprendre des éléments géographiques compris à une certaine distance d'un point latitudinal/longitudinal, et Splitter peut mettre chaque élément géographique dans une ligne de données distincte.
Utilisation du stage Splitter
- Sous Stages de contrôle, cliquez sur Splitter et faites-le glisser sur le canevas, en le plaçant à l'endroit souhaité sur le flux de données, et connectez-le aux stages d'entrée et de sortie.
- Double-cliquez sur Splitter. La boîte de dialogue Options de Splitter apparaît.
- Cliquez sur l'élément déroulant Diviser à pour voir les autres types de liste disponibles pour ce stage. Cliquez sur le type de liste que vous voulez que Splitter génère. La boîte de dialogue Options de Splitter s'ajuste en fonction de votre sélection, affichant les champs disponibles pour ce type de liste.
Vous pouvez aussi cliquer sur le bouton de sélection (...) en regard de l'élément déroulant Diviser à. La boîte de dialogue Schéma de Champ apparaît, affichant le schéma pour les données entrant dans Splitter. Les types de listes s'affichent en gras, suivis des listes individuelles de chaque type. Le format de ces champs s'affiche également (chaîne, double et ainsi de suite). Cliquez sur le type de liste que vous voulez que Splitter crée puis cliquez sur OK. La boîte de dialogue Options de Splitter s'ajuste en fonction de votre sélection, affichant les champs disponibles pour ce type de liste.
- Cliquez sur Enregistrement d'en-tête de sortie pour renvoyer l'enregistrement original avec la liste divisée extraite.
- Cliquez sur Uniquement lorsque la liste d'entrée est vide pour renvoyer l'enregistrement original uniquement en l'absence de liste divisée pour cet enregistrement.
- Sélectionnez les champs que vous voulez que Splitter inclut à la sortie en cochant la case Inclure pour les champs correspondants.
- Cliquez sur OK.
Exemple de Splitter
L'exemple suivant prend la sortie d'un stage d'itinéraire incluant des itinéraires pour la voiture et met chaque itinéraire (ou article de liste) dans une ligne de données. Le flux de données ressemble à ceci :
Le flux de données exécute la fonction de la manière suivante :
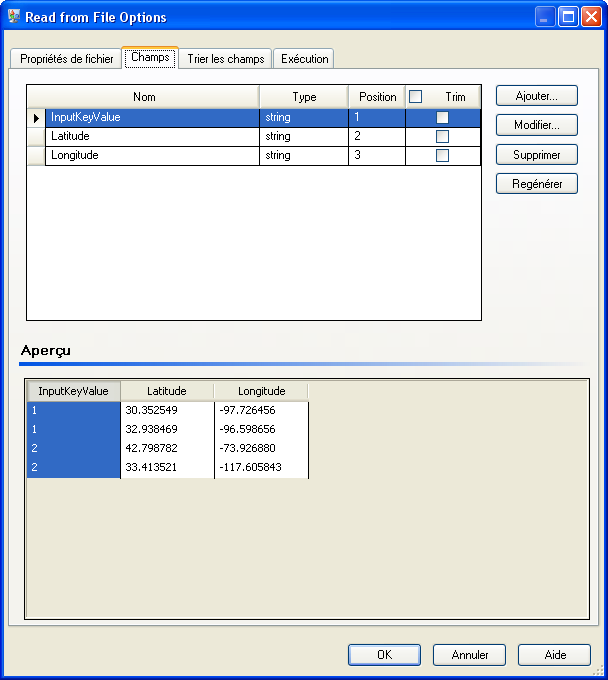
- Le stage Read from File contient des latitudes, longitudes et valeurs clés d'entrée pour vous aider à identifier les points individuels.
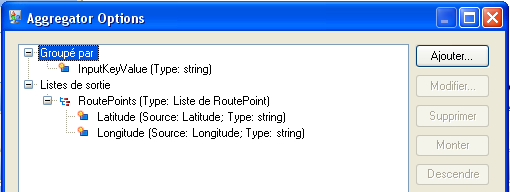
- Le stage Aggregator génère les données à partir du stage Read from File sous forme de schéma (une hiérarchie structurée de données) et identifie le groupe de latitudes et de longitudes en tant que liste de points d'itinéraires, ce qui constitue une étape nécessaire pour le bon fonctionnement du prochain stage.
- Le stage Get Travel Directions du Module Location Intelligence crée un itinéraire à partir d'un emplacement jusqu'à un autre à l'aide des points d'itinéraire de l'étape 2.
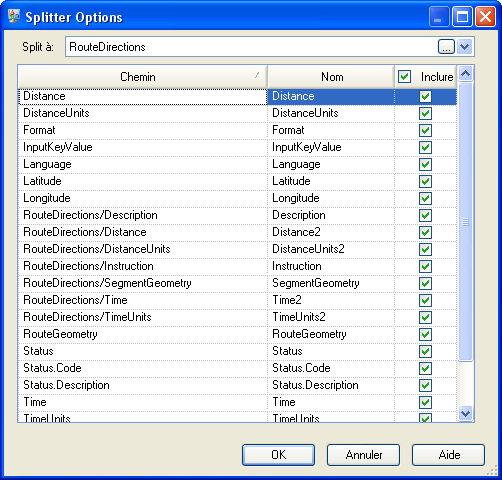
- Le stage Splitter établit la division des données du champ Itinéraire, et inclut tous les champs possibles du stage Get Travel Directions dans les listes de sortie.
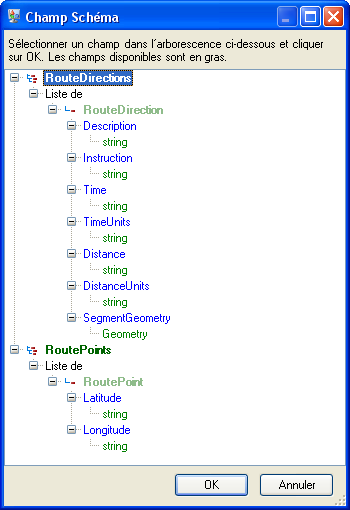
Le schéma est structuré comme suit, avec des Itinéraires et des Points d'itinéraire comme listes disponibles pour ce job :
- Le stage Write to File écrit la sortie dans un fichier.