Aggregator
Aggregator convertit les données texte en données hiérarchiques. Il prend des données d'entrée d'une source unique, crée un schéma (une hiérarchie de données structurée) en regroupant les données en fonction des champs que vous indiquez, puis construit les groupes dans le schéma.
Grouper par
Choisissez le champ à utiliser comme base pour l'agrégation dans une hiérarchie en sélectionnant Grouper par dans l'arborescence et en cliquant sur Ajouter. Les enregistrements disposant de la même valeur dans le champ de votre choix verront leurs données agrégées dans une seule hiérarchie. Si vous sélectionnez plusieurs champs, les données de tous les champs doivent correspondre afin de regrouper les enregistrements dans une hiérarchie.
Par exemple, si vous souhaitez regrouper les données par numéro de compte, vous devez sélectionner le champ du numéro de compte. Tous les enregistrements entrants disposant de la même valeur dans le champ du numéro de compte verront leurs données regroupées dans un seul enregistrement hiérarchique.
Listes de résultats
Les champs que vous sélectionnez sous Listes de résultats déterminent les champs qui sont inclus dans chaque enregistrement créé par Aggregator. Pour ajouter un champ, sélectionnez Listes de résultats puis cliquez sur Ajouter et choisissez l'une des options suivantes :
- Champ existant
- Sélectionnez cette option si vous souhaitez ajouter un champ du flux de données à la hiérarchie.
- Nouveau type de données
- Sélectionnez cette option si vous souhaitez créer un champ parent dans lequel vous pouvez ensuite ajouter des champs enfant.
- Modèle
- Cette option vous permet d'ajouter un champ en fonction des données du stage connecté au port de sortie de Aggregator.
Si vous souhaitez que le champ dispose de champs enfant, cochez la case Liste.
Saisissez le nom du champ dans la zone de texte Nom, ou ne la modifiez pas si celle-ci s'est remplie automatiquement et si le nom vous convient. Gardez à l'esprit que le stage Aggregator n'accepte pas les caractères XML invalides dans les noms de champ ; mais les caractères alphanumériques sont permis, tels que le point (.), le trait de soulignement (_), et le tiret (-).
Cliquez sur Ajouter pour ajouter le champ. Vous pouvez spécifier un autre champ à ajouter au même niveau dans la hiérarchie ou vous pouvez cliquer sur Fermer.
Pour ajouter des champs enfant à un champ existant, sélectionnez le champ parent, puis cliquez sur Ajouter.
Exemple de Aggregator
Un exemple de la fonction de Aggregator consiste à prendre un groupe d'adresses postales et à les transformer en itinéraires routiers. Vous pouvez réaliser ceci à l'aide de deux points : un point de départ et un point d'arrivée, ou bien vous pouvez placer plusieurs points le long d'un itinéraire. Le flux de données correspondant à ce type de fonction pourrait ressembler à ceci :
Le flux de données exécute la fonction de la manière suivante :
- Le stage Read from File contient les adresses postales dans un fichier plat. Les champs de ce fichier sont les suivants :
- un ID (Identifiant), qui identifie une adresse particulière dans le fichier.
- un Type, qui indique si l'adresse est une adresse « Destinataire » ou « Expéditeur ».
- un champ AddressLine1, qui fournit la rue de l'adresse.
- un champ LastLine, qui comprend des informations telles que la ville, l'État, et/ou le code postal.
- La Transformation de champ entre le stage Read from File et le stage Math modifie le format du champ ID de chaîne en double parce que le stage Math n'accepte pas les données chaîne.

- Le stage Math génère une expression qui établit un champ Group ID (Identifiant du groupe) à utiliser en aval dans le flux de données. Dans cet exemple, celui-ci calcule le Group ID comme un plancher (floor) de, ou un arrondi au chiffre inférieur de, la valeur du champ ID divisé par 2. Par conséquent, pour un ID de 3, l'expression sera 3/2, qui est égal à 1,5. Lorsque vous arrondissez 1,5 au chiffre inférieur, vous obtenez 1. Si l'identifiant est 2, l'expression sera de 2/2, égal à 1, et il n'y aura donc nul besoin d'arrondir au chiffre inférieur. Donc, les ID de 2 et 3 ont un même Group ID de 1.

- Geocode US Address obtient les latitudes et les longitudes de chaque adresse.
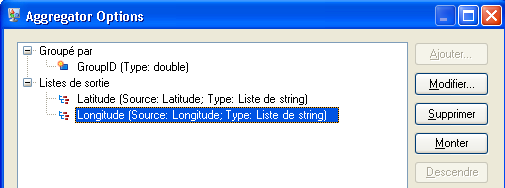
- Le stage Aggregator établit le regroupement des données par le champ GroupID (identifiant du groupe) et les listes de sortie doivent inclure les points de l'itinéraire composés de leurs latitudes et longitudes. Les instructions ci-dessous montrent comment configurer manuellement le stage Aggregator pour ce flux de données.
- Double-cliquez sur le stage Aggregator puis sur Groupé par.
- Sélectionnez le champ GroupID et cliquez sur OK. Ce champ vous permet d'inclure des points d'itinéraire (Route Points) pour les prochains stages du flux de données. Les points d'itinéraire sont des éléments essentiels pour un flux de données qui produit des itinéraires.
- Double-cliquez sur Listes de sortie. La boîte de dialogue Options du champ s'affiche.
- Sélectionnez Nouveau type de données. Dans le champ Type name, entrez RoutePoint. Dans le champ Name, entrez RoutePoints. Par défaut, il s'agit d'une liste qui ne peut être modifiée, donc la case à cocher est grisée.
- Appuyez sur OK.
- Cliquez sur RoutePoints (points d'itinéraire) et cliquez sur Ajouter. La boîte de dialogue Options du champ s'affiche à nouveau.
- Les points d'itinéraires sont composés de latitudes et longitudes, c'est pourquoi nous devons d'abord ajouter un Champ existant à partir du champ d'entrée existant Latitude. Le champ Name se remplit de manière automatique.
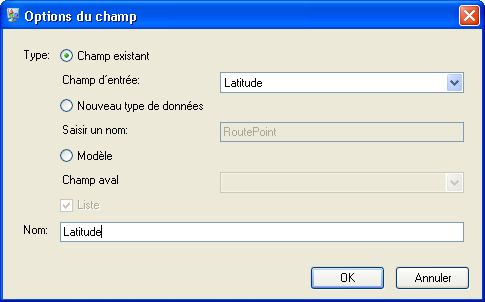
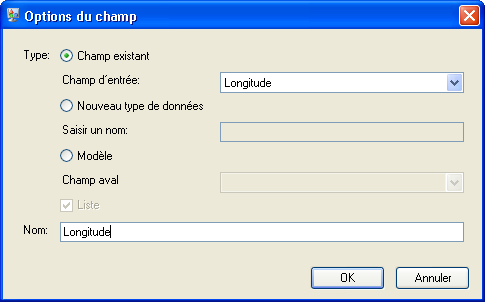
Répétez cette étape pour la Longitude.
Le stage Aggregator une fois terminé ressemblera à ceci :
- Get Travel Directions fournit des itinéraires voitures à partir des ID de points 0, 2, et 4 jusqu'aux ID de points 1, 3, et 5, respectivement.
- Le stage Splitter établit la division des données du champ Itinéraire, et inclut tous les champs possibles du stage Get Travel Directions dans les listes de sortie.
- Le stage Write to File écrit les directions dans un fichier de sortie.