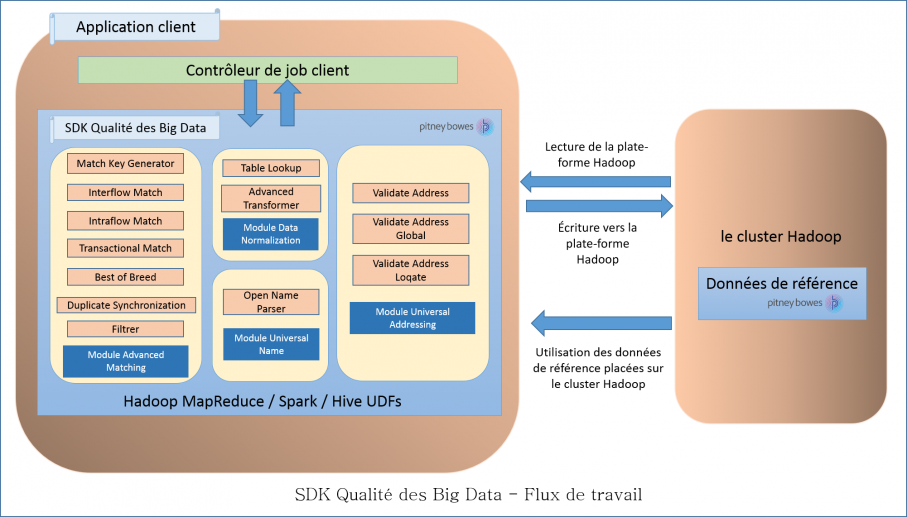
Flux de travail
Pour utiliser le SDK, les composants nécessaires sont les suivants :
- Installation SDK qualité des Big Data
- Le fichier JAR SDK qualité des Big Data doit être installé sur votre système et disponible pour être utilisé par votre application.
- Application client
- L'application Java que vous devez créer pour appeler et exécuter les opérations de qualité des données requises à l'aide du SDK. Le fichier JAR SDK qualité des Big Data doit être importé dans votre application Java.
- Plate-forme Hadoop
- Lors de l'exécution d'un job à l'aide de SDK qualité des Big Data, les données sont tout d'abord lues à partir de la plate-forme Hadoop configurée et selon le traitement approprié, les données de sortie sont écrites dans la plate-forme Hadoop.
Pour ce faire, les détails d'accès de la plate-forme Hadoop doivent être configurés correctement sur votre machine. Pour plus d'informations, reportez-vous à la section Résumé.
- Données de référence
- Les données de référence, requises par SDK qualité des Big Data, sont placées sur le cluster Hadoop.
- API Java
-
Pour utiliser l'API Java, vous pouvez choisir de placer les données de référence à l'un des emplacements ci-dessous :
- Nœuds de données locaux : les données de référence sont placées sur tous les nœuds de données disponibles dans le cluster.Remarque : Il ne s'agit pas d'une méthode infaillible.
- Hadoop Distributed File System (HDFS): Les données de références sont placées dans un répertoire HDFS. Ceci garantit que vos données sont parfaitement sécurisées.
- Nœuds de données locaux : les données de référence sont placées sur tous les nœuds de données disponibles dans le cluster.
- Fonctions définies par l'utilisateur (UDF) Hive
- Pour utiliser les UDF Hive, vous devez placer les données de référence sur chaque nœud de données local du cluster.
Remarque : Le SDK permet également une mise en cache distribuée pour améliorer les performances.