Procesamiento distribuido
Si tiene un trabajo muy complejo, o está procesando un grupo de datos muy extenso (por ejemplo, uno que contiene millones de registros), es posible que pueda mejorar el rendimiento del flujo de datos al distribuir el procesamiento del flujo de datos hacia múltiples instancias del servidor de Spectrum™ Technology Platform en uno o más servidores físicos.
Una vez que se haya configurado su entorno de agrupación en clústeres, puede crear un procesamiento distribuido en un flujo de datos creando subflujos para las partes del flujo de datos que desea que se distribuyan hacia los diversos servidores. Spectrum™ Technology Platform gestiona la distribución del procesamiento de manera automática luego de que usted especifica solo algunas opciones de configuración del subflujo.
El siguiente diagrama ilustra el funcionamiento del procesamiento distribuido:
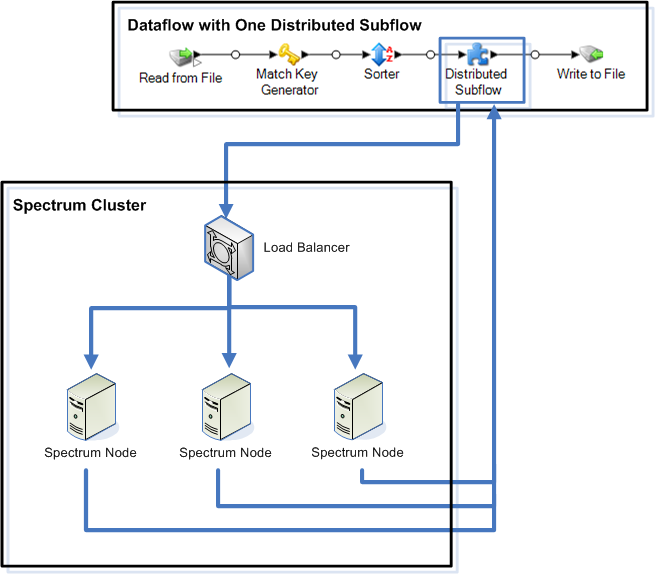
A medida de que se leen los registros en el subflujo, los datos son agrupados en lotes. Estos lotes son luego escritos en el clúster y distribuidos de manera automática al nodo en el clúster que procesa el lote. Este procesamiento se denomina "microflujo". El subflujo puede ser configurado para admitir que muchos microflujos se procesen en simultáneo, lo que mejora potencialmente el rendimiento del flujo de datos. Cuando la instancia distribuida termina de procesar un microflujo, envía el resultado de vuelta al flujo principal.
A mayor cantidad de nodos Spectrum™ Technology Platform, más microflujos pueden procesarse en simultáneo, lo que permite escalar el entorno según sea necesario para obtener el rendimiento necesario.
Cuando está definido, el entorno agrupado es fácil de mantener, porque todos los nodos del clúster sincronizan su configuración, lo que significa que los ajustes realizados mediante la consola de administración y los flujos de datos diseñados en Enterprise Designer están disponibles automáticamente en todas las instancias.