Configuración de instancias de ejecución locales
Cada etapa de un flujo de datos opera de forma asincrónica en su propio subgrupo y es independiente de cualquier otra etapa, lo que permite el procesamiento paralelo de las etapas de un flujo de datos y la utilización de más de una instancia de ejecución por etapa. Esta característica es útil en los flujos de datos donde algunas etapas procesan datos más rápido que otras, lo que puede derivar en una distribución desigual del trabajo entre los subgrupos. Por ejemplo, considere un flujo de datos que consiste en las siguientes etapas:

Según la configuración de las etapas, es posible que la etapa Validate Address (Validación de direcciones) procese los registros más rápidamente que la etapa Geocode US Address (Geocodificación de direcciones en Estados Unidos). Si eso sucede, en algún punto durante la ejecución del flujo de datos, la etapa Validate Address habrá procesado todos los registros, mientras que la etapa Geocode US Address todavía tendrá registros por procesar. Para mejorar el rendimiento de este flujo de datos, es necesario mejorar el rendimiento de la etapa más lenta; en este caso, Geocode US Address. Una forma de hacerlo es especificando múltiples instancias de ejecución de la etapa. Configurar la cantidad de instancias de ejecución en dos, por ejemplo, significa que habrá dos instancias de esa etapa disponibles para procesar registros, cada una en su propio subgrupo.
El siguiente procedimiento describe cómo configurar una etapa para usar múltiples instancias de ejecución.
-
Haga clic en Ejecución.
Por ejemplo, a continuación se muestra el botón Ejecución en la etapa Geocode US Address.
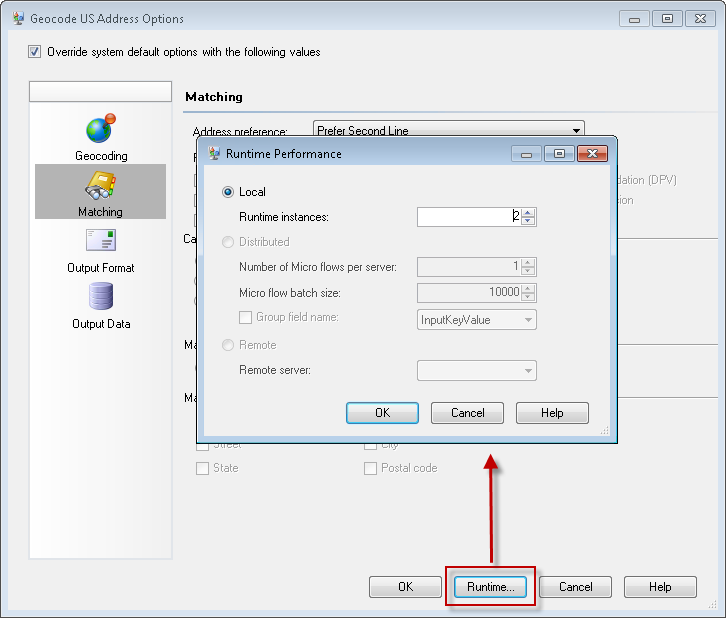 Nota: No todas las etapas pueden usar múltiples instancias de ejecución. Si no existe botón Ejecutar en la parte inferior de la ventana de la etapa, esta última no puede usar múltiples instancias de ejecución.
Nota: No todas las etapas pueden usar múltiples instancias de ejecución. Si no existe botón Ejecutar en la parte inferior de la ventana de la etapa, esta última no puede usar múltiples instancias de ejecución.