This procedure describes how to use an Intraflow Match stage to identify groups of records within a single data source (such as a file or database table) that are related to each other based on the matching criteria you specify. The dataflow groups records into collections and writes the collections to an output file.
-
In Enterprise Designer, create a new dataflow.
-
Drag a source stage onto the canvas.
-
Double-click the source stage and configure it. See the Dataflow Designer's Guide for instructions on configuring source stages.
-
Drag a Match Key Generator stage onto the canvas and connect it to the source stage.
For example, if you are using a Read from File source stage, your dataflow would now look like this:
Match Key Generator creates a non-unique key for each record,
which can then be used by matching stages to identify groups of potentially duplicate
records. Match keys facilitate the matching process by allowing you to group records by
match key and then only comparing records within these groups.
-
Double-click Match Key Generator.
-
Click Add.
-
Define the rule to use to generate a match key for each record.
Table 1. Match Key Generator Options
|
Option Name
|
Description / Valid Values
|
|
Algorithm
|
Specifies the algorithm to use to generate the match key. One of the following:
- Consonant
- Returns specified fields with consonants removed.
- Double Metaphone
- Returns a code based on a phonetic representation of their characters. Double
Metaphone is an improved version of the Metaphone
algorithm, and attempts to account for the many
irregularities found in different languages.
- Koeln
- Indexes names by sound as they are pronounced in German. Allows names with the same
pronunciation to be encoded to the same representation
so that they can be matched, despite minor differences
in spelling. The result is always a sequence of numbers;
special characters and white spaces are ignored. This
option was developed to respond to limitations of
Soundex.
- MD5
- A message digest algorithm that produces a 128-bit hash value. This algorithm is commonly used to check data integrity.
- Metaphone
- Returns a Metaphone coded key of selected fields. Metaphone is an algorithm for coding
words using their English pronunciation.
- Metaphone (Spanish)
- Returns a Metaphone coded key of selected fields for the Spanish language. This
metaphone algorithm codes words using their Spanish
pronunciation.
- Metaphone 3
- Improves upon the Metaphone and Double Metaphone algorithms with more exact consonant and internal vowel settings that allow you to produce words or names more or less closely matched to search terms on a phonetic basis. Metaphone 3 increases the accuracy of phonetic encoding to 98%. This option was developed to respond to limitations of Soundex.
- Nysiis
- Phonetic code algorithm that matches an approximate pronunciation to an exact spelling and indexes words that are pronounced similarly. Part of the New York State Identification and Intelligence System. Say, for example, that you are looking for someone's information in a database of people. You believe that the person's name sounds like "John Smith", but it is in fact spelled "Jon Smyth". If you conducted a search looking for an exact match for "John Smith" no results would be returned. However, if you index the database using the NYSIIS algorithm and search using the NYSIIS algorithm again, the correct match will be returned because both "John Smith" and "Jon Smyth" are indexed as "JAN SNATH" by the algorithm.
- Phonix
- Preprocesses name strings by applying more than 100 transformation rules to single characters or to sequences of several characters. 19 of those rules are applied only if the character(s) are at the beginning of the string, while 12 of the rules are applied only if they are at the middle of the string, and 28 of the rules are applied only if they are at the end of the string. The transformed name string is encoded into a code that is comprised by a starting letter followed by three digits (removing zeros and duplicate numbers). This option was developed to respond to limitations of Soundex; it is more complex and therefore slower than Soundex.
- Soundex
- Returns a Soundex code of selected fields. Soundex produces a fixed-length code based
on the English pronunciation of a word.
- Substring
- Returns a specified portion of the selected field.
|
|
Field name
|
Specifies the field to which you want to apply the selected algorithm to generate the match key. For example, if you select a field called LastName and you choose the Soundex algorithm, the Soundex algorithm would be applied to the data in the LastName field to produce a match key.
|
|
Start position
|
Specifies the starting position within the specified field. Not all algorithms allow you to specify a start position.
|
|
Length
|
Specifies the length of characters to include from the starting position. Not all algorithms allow you to specify a length.
|
|
Remove noise characters
|
Removes all non-numeric and non-alpha characters such as hyphens, white space, and other special characters from an input field.
|
|
Sort input
|
Sorts all characters in an input field or all terms in an input field in alphabetical order.
- Characters
- Sorts the characters values from an input field prior to creating a unique ID.
- Terms
- Sorts each term value from an input field prior to creating a unique ID.
|
-
When you are done defining the rule click OK.
-
If you want to add additional match rules, click Add and add them, otherwise click OK when you are done.
-
Drag an Intraflow Match stage onto the canvas and connect it to the Match Key Generator stage.
For example, if you are using a Read from File source stage, your dataflow would now look like this:

-
Double-click Intraflow Match.
-
In the Load match rule field, select one of the predefined match
rules which you can either use as-is or modify to suit your needs. If you want
to create a new match rule without using one of the predefined match rules as a
starting point, click New. You can only have one custom
rule in a dataflow.
Note: The Dataflow Options feature in Enterprise Designer enables the match rule to be exposed
for configuration at runtime.
-
In the Group by field, select MatchKey.
This will place records that have the same match key into a group. The match rule is applied to records within a group to see if there are duplicates. The match key for each record will be generated by the Generate Match Key stage you configured earlier in this procedure.
-
For information about modifying the other options, see Building a Match Rule.
-
Click OK to save your Intraflow Match configuration and return to the dataflow canvas.
-
Drag a sink stage onto the canvas and connect it to the Generate Match key stage.
For example, if you were using a Write to File sink stage your dataflow would look like this:

-
Double-click the sink stage and configure it.
For information on configuring sink stages, see the Dataflow Designer's Guide.
You now have a dataflow that will match records from a single source.
Example of Matching Records in a Single Data Source
As a data steward for a credit card company, you want to analyze your customer database and find out which addresses occur multiple times and under what names so that you can minimize the number of duplicate credit card offers sent to the same household.
This example demonstrates how to identify members of the same household by comparing information within a single input file and creating an output file containing one record per household.
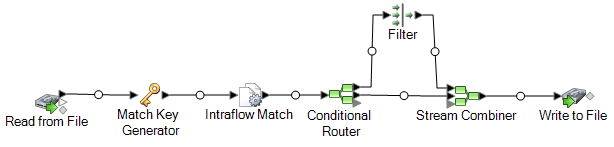
The Read from File stage reads in data that contains both unique records for each household and records that are potentially from the same household. The input file contains names and addresses.
The Match Key Generator creates a match key which is a non-unique key shared by like records that identify records as potential duplicates.
The Intraflow Match stage compares records that have the same match key and marks each record as either a unique record or as one of multiple records for the same household.
The Conditional Router sends records that are collections of records for each household to the Filter stage, which filters out all but one of the records from each household, and sends it on to the Stream Combiner stage. The Conditional Router stage also sends unique records directly to Stream Combiner.
Finally, the Write to File stage creates an output file that contains one record for each household.