Options
- In Enterprise Designer, double-click the Write to Search Index stage on the canvas.
- Enter a Name for the index.
-
Select a Write mode. When you regenerate an index, you
have options related to how the new data should affect the existing data.
- Create or Overwrite—New data will overwrite the existing data and the existing data will no longer be in the index.
- Update or Append—New data will overwrite existing data, and any new data that did not previously exist will be added to the index.
- Append—New data will be added to the existing data and the existing data will remain in tact.
- Delete—Data for the selected field will be deleted from the search index.
-
Select the Key field on the basis of which you want to
Update or Append or Delete the
records.
- In case of Create or Overwrite mode, the
Key field needs to be unique for Elastic search
indexes (used in a distributed environment). If you leave the field blank,
all the records get stored in the index irrespective of any duplication.
However, you will not be able to perform any write operation, such as
update, append, and delete on this index. The following table explains the
indexing behavior if the Key field is non-unique for
Lucene and Elastic search indexes.
Write mode Key field Lucene search index Elastic search index Create or Overwrite
Duplicate records with same Key field All the records are stored. Note: The duplicate records with same key field get overwritten as soon as you run the update operation.All duplicate records with the same Key field are overwritten. Update or Append Duplicate records with same Key field Duplicates are overwritten. Duplicates are overwritten.
- In case of Create or Overwrite mode, the
Key field needs to be unique for Elastic search
indexes (used in a distributed environment). If you leave the field blank,
all the records get stored in the index irrespective of any duplication.
However, you will not be able to perform any write operation, such as
update, append, and delete on this index. The following table explains the
indexing behavior if the Key field is non-unique for
Lucene and Elastic search indexes.
- Check the Batch commit box if you want to specify the number of records to commit in a batch while creating the search index. Then enter that number in the Batch size field. Default is 5000.
-
Select an Analyzer to build:
- Standard—Provides a grammar-based tokenizer that contains a superset of the Whitespace and Stop Word analyzers. Understands English punctuation for breaking down words, knows words to ignore (via the Stop Word Analyzer), and performs technically case-insensitive searching by conducting lowercase comparisons. For example, the string “Pitney Bowes Software” would be returned as three tokens: “pitney”, “bowes”, and “software”. For a comparison of Standard and Keyword analyzers, see Standard and Keyword Analyzer.
- Whitespace—Separates tokens with whitespace. Somewhat of a subset of the Standard Analyzer in that it understands word breaks in English text based on spaces and line breaks.
- Stop Word—Removes articles such as "the," "and," and "a" to shrink the index size and increase performance.
- Keyword—Creates a single token from a stream of data and keeps is as is. For example, the string “Pitney Bowes Software” would be returned as just one token “Pitney Bowes Software”. For a comparison of Standard and Keyword analyzers, see Standard and Keyword Analyzer.
- Russian—Supports Russian-language indexes and type-ahead services. Also supports many stop words and removes articles such as "and," "I," and "you" to shrink the index size and increase performance.
- German—Supports German-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Danish—Supports Danish-language indexes and type-ahead services. Also supports many stop words and removes articles such as "at" "and," and "a" to shrink the index size and increase performance.
- Dutch—Supports Dutch-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Finnish—Supports Finnish-language indexes and type-ahead services. Also supports many stop words and removes articles such as "is" "and," and "of" to shrink the index size and increase performance.
- French—Supports French-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Hungarian—Supports Hungarian-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Italian—Supports Italian-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Norwegian—Supports Norwegian-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Portuguese—Supports Portuguese-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Spanish—Supports Spanish-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Swedish—Supports Swedish-language indexes and type-ahead services. Also supports many stop words and removes articles such as "the" "and," and "a" to shrink the index size and increase performance.
- Hindi—Supports Hindi-language indexes and type-ahead services. Also supports many stop words and removes articles such as "by" "and," and "a" to shrink the index size and increase performance.
- To update the analyzer of all fields present in the list, Select an analyzer from update Analyzers to... drop down.
-
To reload the schema from the server, click Reload
Schema.
Note: You can change the field name by typing the new name directly in the Fields column. However, you cannot change the Stage Fields name or the Type.
- To selectively add/remove fields from your input source, click Quick Add. The Quick Add pop-up window displays a list of all the fields from the input source. Select the fields that you want to add and click OK.
- Select the field(s) whose data you want to store. For example, using an input file of addresses, you could index just the Postal Code field but choose to store the remaining fields (such as Address Line 1, City, State) so the entire address is returned when a match is found using the index search.
-
Select the field(s) whose data you want to be added to the index for a search
query.
Note: If you want to delete certain fields, select those and click Delete.
- If necessary, change the analyzer for any field that should use something other than what you selected in the Analyzer field.
- Click OK.
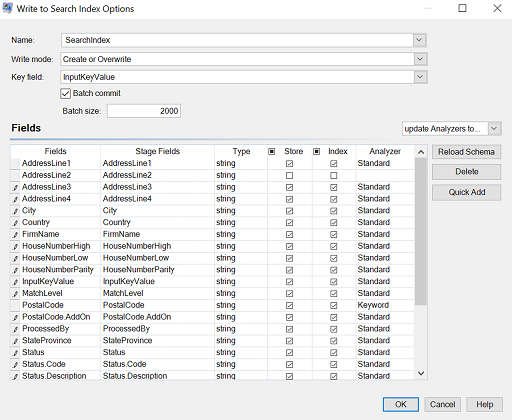
The screen below shows an example of the completed Write to Search Index Options
stage:
- A name of "SearchIndex"
- Create or Overwrite Write mode
- A Key Field "InputKeyValue"
- A batch commit size of 2000 records
- The use of the Standard analyzer
- A list of fields that are in the input file
- A list of fields that will be stored along with the index data. In our case only AddressLine2 will not be stored.
- A list of fields that will comprise the index. In our case only AddressLine2 will not be indexed.
- The use of the Keyword analyzer for the PostalCode field