Tipos de flujos
Un flujo de datos es una serie de operaciones que toman datos desde cierto origen, los procesan y luego escriben la salida en algún destino. El procesamiento de los datos puede ser desde una simple clasificación hasta acciones más complejas de enriquecimiento y calidad de datos. El concepto de un flujo de datos es simple, pero se pueden diseñar flujos de datos muy complejos con rutas de bifurcaciones, varios orígenes de entrada y diversos destinos de salida.
Existen cuatro tipos de flujo de datos: trabajos, servicios, subflujos y flujos de proceso.
Trabajo
Un trabajo es un flujo de datos que realiza procesamientos en lote. Un trabajo lee los datos de uno o más archivos o bases de datos, los procesa y escribe los datos de salida en uno o más archivos o bases de datos. Puede ser ejecutado de forma manual en Enterprise Designer o se puede ejecutar desde una línea de comando utilizando el ejecutador de trabajos.
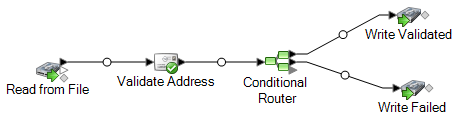
El siguiente flujo de datos es un trabajo. Cabe destacar que este flujo de datos utiliza la etapa Read from File (Lectura desde archivo) como entrada y dos etapas Write to File (Escritura en archivo) como salida.
Servicios
Un servicio es un flujo de datos al que puede acceder como un servicio web o por medio del uso de la API Spectrum™ Technology Platform. Se pasa un registro al servicio y opcionalmente se especifican las opciones que se van a usar al procesarlo. Este servicio procesa los datos y los devuelve.
Algunos servicios están disponibles cuando se instala un módulo. Por ejemplo, cuando se instala el módulo Universal Addressing (Direcciones universales), el servicio ValidateAddress está disponible en su sistema. En otros casos, debe crear un servicio en Enterprise Designer y, luego, exponerlo en su sistema como un servicio definido por el usuario. Por ejemplo, las etapas del módulo Location Intelligence (Inteligencia de localización) no están disponibles como servicios a menos que antes se cree un servicio utilizando las etapas del módulo.
También es posible diseñar sus propios servicios personalizados en Enterprise Designer. Por ejemplo, el siguiente flujo de datos determina si una dirección corre el riesgo de inundarse:

Subflujo
Un subflujo es un flujo de datos que se puede reutilizar dentro de otros flujos de datos. Los subflujos son útiles cuando se desea crear procesos reutilizables, que se puedan incorporar fácilmente en los flujos de datos. Por ejemplo, es posible que quiera crear un subflujo que realice una desduplicación con cierta configuración en cada etapa, de modo que pueda usar el mismo proceso de desduplicación en varios flujos de datos. Para hacer esto puede crear un subflujo como el siguiente:
Posteriormente, puede utilizar este subflujo en un flujo de datos. Por ejemplo, puede utilizar el subflujo de desduplicación dentro de un flujo de datos que realice geocodificación , de modo que los datos se desdupliquen antes de la operación de geocodificación:
En este ejemplo, los datos se leerían desde una base de datos, luego se pasarían al subflujo de desduplicación, donde se procesarían a través del Match Key Generator, luego Intraflow Match, luego Best of Breed, y finalmente se enviarían desde el subflujo y en la siguiente etapa en el flujo de datos principal, en este caso Geocode US Address. Los subflujos están representados por un icono de sección de rompecabezas en el flujo de datos, como se muestra anteriormente.
Los subflujos que se guardan y exponen aparecen en la carpeta Etapas definidas por el usuario en Enterprise Designer.
Flujo de proceso
Un flujo de proceso ejecuta una serie de actividades, como trabajos y aplicaciones externas. Cada actividad en el flujo de proceso se ejecuta después de que finalice la actividad anterior. Los flujos de proceso son útiles si desea ejecutar varios flujos de datos uno tras otro, o si desea ejecutar un programa externo. Por ejemplo, un flujo de proceso puede ejecutar un trabajo para estandarizar nombres, validar direcciones y, luego, recurrir a una aplicación externa a fin de ordenar los registros en la secuencia correspondiente para solicitar descuentos postales. Un flujo de proceso de ese tipo tendría la siguiente apariencia:

En este ejemplo, los trabajos Estandarizar nombres y Validar direcciones son trabajos expuestos en el servidor Spectrum™ Technology Platform. Ejecutar programa invoca una aplicación externa y la actividad Sin errores indica el final del flujo de proceso.