同世帯の個人を識別
このデータフロー テンプレートは、単一の入力ファイル内で情報を比較し、世帯コレクションの出力ファイルを作成することによって、同じ世帯のメンバーを特定する方法を示します。
ビジネス シナリオ
クレジットカード会社のデータ管理責任者が、顧客データベースを分析し、複数のレコードに重複して現れる住所とその住所に住む顧客の氏名を洗い出して、同じ住所に重複して送付される郵便物とクレジットカード契約勧誘の数を最小限にすることを検討しています。
以下のデータフローは、このビジネス シナリオの解決策を示しています。
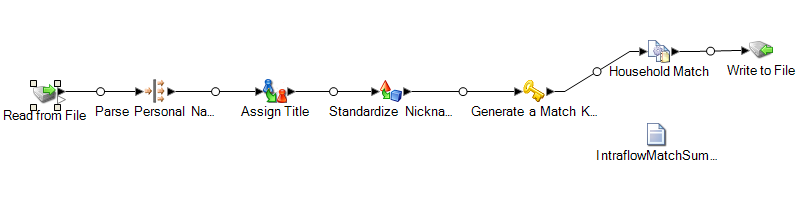
このデータフロー テンプレートは Enterprise Designer で使用できます。 に移動し、[HouseholdRelationships] を選択します。このデータフローでは、Advanced Matching モジュール、Data Normalization モジュール、および Universal Name モジュールが必要です。
このデータフローでは、入力ファイルに含まれる各レコードに対して次の処理が行われます。
Read from File
このステージでは、パースする名前が記録されているファイルの名前、格納場所、およびレイアウトを識別します。ファイルには、男性と女性の両方の名前が含まれています。
Open Name Parser
Open Name Parser では、名前フィールドをチェックして、Spectrum™ Technology Platform名前データベース ファイルに格納されている名前データと比較します。この比較結果に基づいて、名前データが [First]、[Middle]、[Last] の各名前フィールドに分割され、エンティティ タイプと性別がすべての名前に割り当てられます。また、名前データに加えて、パターン認識も使用されます。
Standardize Nicknames
このテンプレートでは、Table Lookup ステージを Standardize Nicknames と呼びます。Standardize Nicknames ステージでは、Nicknames.xml データベースに名を検索し、その名前にフォーマルな表記があればそれでニックネームを置き換えます。例えば、Tommy という名前は Thomas で置き換えます。
Transformer
このテンプレートでは、Transformer ステージを Assign Titles と呼びます。Assign Titles ステージでは、カスタム スクリプトを使って、Parse Personal Name ステージからのデータ ストリーム出力中に各行を検索し、GenderCode 値に基づいて TitleOfRespect 値を割り当てます。
使用するカスタム スクリプトを以下に示します。
if (row.get('TitleOfRespect') == '')
{
if (row.get('GenderCode') == 'M')
row.set('TitleOfRespect', 'Mr')
if (row.get('GenderCode') == 'F')
row.set('TitleOfRespect', 'Ms')Assign Titles ステージでは、GenderCode フィールドで M を検出するたびに TitleOfRespect の値を Mr に設定します。Assign Titles ステージでは、GenderCode フィールドで F を検出するたびに TitleOfRespect の値を Ms に設定します。
Match Key Generator
Match Key Generator では、アルゴリズムと入力ソース フィールドで構成されるユーザ定義ルールを処理して、マッチ キー フィールドを生成します。マッチ キーは、重複の可能性があるレコードを意味する類似レコードに共通して与えられる非ユニーク キーです。マッチ キーは、同じマッチ キーを含むレコードのみを比較するために簡易的なマッチングに使われます。マッチ キーは、入力フィールドで構成されます。指定する入力フィールドごとに、そのフィールドで実行されるアルゴリズムが選択されます。その後、各フィールドの結果を連結して、単一のマッチ キー フィールドが作成されます。
このテンプレートでは、SubString (LastName (1:3)) と SubString (PostalCode (1:5)) の 2 つのマッチ キー フィールドが定義されています。
例えば、次のような入力住所があり、
FirstName - Fred
LastName - Mertz
PostalCode - 21114-1687
次のルールが指定されている場合、
|
入力フィールド |
開始位置 |
長さ |
|---|---|---|
|
LastName |
1 |
3 |
|
PostalCode |
1 |
5 |
上記のルールと入力データを使うと、次のようなキーになります。
Mer21114
Household Match
このデータフロー テンプレートでは、Intraflow Match ステージを Household Match と呼びます。このステージでは、単一の入力ストリーム内の類似するデータ レコード間でマッチを検出します。また、マッチしたレコードは、名前/住所以外の情報で修飾できます。このマッチング エンジンを使うと、他のステージで定義または作成されたフィールドに基づいて階層型のルールを作成できます。
マッチを検出するレコード ストリームのほかに、比較の対象とするフィールド、スコアの計算方法、および正しいマッチングと見なす全般的な条件も設定されます。
このテンプレートでは、LastName および AddressLine1 の比較を実行するカスタム マッチング ルールを作成します。Interflow Summary Report のデータを生成するために、[分析用データを生成する] チェック ボックスを選択します。
マッチング階層を作成する際は、以下のガイドラインに従ってください。
- 親ノード名は一意な名前でなければなりません。フィールドにすることはできません。
- 子フィールドは、Spectrum™ Technology Platformのデータ タイプ フィールドである必要があります。つまり、1 つ以上のコンポーネントを通じて使用できるフィールドでなければなりません。
- 親の下のすべての子は、同じ論理演算子を使用する必要があります。コネクタを結合するには、まず中間の親ノードを作成する必要があります。
- 親ノードのしきい値を子のしきい値より低くすることはできません。
- 親ノードにしきい値がなくてもかまいません。
Write to File
テンプレートには 1 つの Write to File ステージがあり、このステージで住所を世帯のコレクションとして表示するテキスト ファイルを作成します。
Intraflow Summary Report
このテンプレートには、Intraflow Match Summary Report が含まれます。ジョブを実行した後で、[実行の詳細] ウィンドウ内で [レポート] を展開し、[IntraflowMatchSummary] をクリックします。
Intraflow Match Summary Report には、処理済みレコードの統計情報が表示され、レコード数と全体のマッチング スコアがグラフィカルな棒グラフで示されます。